Year In Review 2019 Edition
January
In January I tried to make a photo gallery hosting platform with ML sprinkled on top, but got sidetracked when I couldn’t figure out how to compile TensorFlow (spoiler: their directions were wrong and their dependencies break every minor point release).
To vent my frustration with TensorFlow and the status of Google’s “throw it over the fence” open source model, I spent 5 weeks creating a 3 hour long YouTube Video about compiling TensorFlow in real time (but there’s also a 30 minute version where the compile goes much faster.
February
After publishing the TensorFlow compile video, my ambition for the ML-based photo gallery hosting platform waned.
I ran some of my old travel and miscellaneous pictures through different models, but never created the final web front end to properly cluster and display everything. Maybe next year?
Some examples of image model successes and failures:






The model thought these were cell phones (but it detected their bounds and masked them out very well):
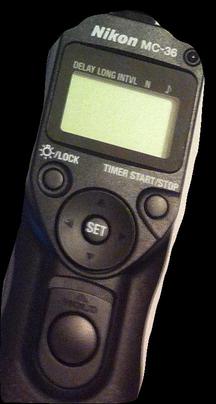


The model got it right calling this a remote:

March
Fixed zig doc errors outside the test suite
April
Fixed a zig command line crash
Fixed a critical documentation error which also led to a diagnostic feature request
Minor contributions from March mentioned in zig release notes for April
Merged a contributed fix to my Signal Backup Archiver Utility
May
From March to May I spent over 100 hours of my uncompensated personal time improving the jemalloc build system:
- I originally contributed some improvements in January 2017 but those went mostly ignored (and they weren’t really complete)
- I completed my implementation through March to May of 2019
- In April I wrote at length explaining the reasons behind each implementation decision to make life for future maintainers easier
- when I was reasonably done, I thought I’d ask facebook (the corporate maintainer of the project) for some compensation since I’ve spent over 200 hours of my own time improving the library, and they weren’t very receptive to the idea. Meanwhile, they are happy to pay $5 billion in fines for privacy violations, but they can’t compensate public developers giving them hundreds of hours of work for free.
also, the world’s 500 richest people increased their wealth by $1.2 trillion this year, so, yeah, pay for your damn software. We’re tired of subsidizing your profits and private billions with our free work.
thanks, internet! I’ve officially given up on any long-form open source software work. Sure, if I see a small 1-5 line fix, I’ll throw it in, but I have no interest in giving companies my work for free without any avenue to achieve compensation—and especially since public developers are expected to never ask for compensation or get shamed if we attempt to ask to have our work properly valued by companies making hundreds of billions of dollars a year who still insist they don’t have to pay for software.
Even without having my build system improvements merged into the official project for 3 years, other projects like Apache MXNet have taken my patches into their own platforms because building with CMake is important these days and CMake helps thousands of projects integrate libraries better than relying on 1980s-mindset autoconf tools.
June / July
Concurrently with the jemalloc upgrades, I spent the first half of the year improving and extending my memcached and redis replacements:
- Carrier Cache ($5,000 per server per year)
- Carrier DB ($6,500 per server per year)
Carrier Cache and Carrier DB allows you to run the most memory efficient databases and caches possible.
When I say “the most efficient possible,” I mean ever possible.
There is not one single wasted bit in any of the custom data structures inside Carrier Cache and Carrier DB. The custom data structures belong to a class of work I call “impossible software,” because it’s practically impossible to duplicate the results in any corporate environment. The work is a single continual effort expressed over 5+ years with a purposeful goal in mind. Singular years-long work can’t be done under traditional corporate umbrella departments. The data structures in Carrier Cache and Carrier DB are designed to use all advantages of modern computing architectures and processors so you can serve the most data possible using the least amount of RAM physically possible.
But, as we’ve seen with all server-side server software for the past 10 years, if you make your brilliant new systems completely open source, AWS and GCP and Azure will just copy them then host them privately and make money off your work, experience, R&D, and market shaping without compensating you at all.
So, for Carrier Cache and Carrier DB, we have a different model. You want to run the most efficient and most secure and most feature rich in-memory databases ever created? You’ve gotta pay for the work we put into it.
It’s such an odd concept trying to convince people to pay for software. We don’t walk into Arby’s and demand a lunch for free just because the marginal cost of them serving lunch to us is negligible. So, yes, we must charge for software. I can’t live off github likes alone.
New Carrier DB/Cache features in 2019:
- two new data structures in Carrier DB for the most efficient
settype storage- optimized auto-deduplicating sets
- optimized integer-only sets taking advantage of SIMD operations
- automatic namespaces
- Carrier Cache and Carrier DB support locking clients into a namespace per-virtual-network
- client namespace improvements
- clients can create namespaces to any nested depth
- clients can also lock their current namespace so future operations can’t escape the namespace
- support for multiple TLS certificates per network (for RSA + ECDSA certs)
- greatly improved TLS performance all around
- Custom Switchable Output in Carrier DB
- Carrier DB can now respond to requests in JSON or even Python-formatted replies
- Syntax can be specified by each client when you connect or you can set a default output syntax per virtual server
- startup script inclusion
- you can configure each virtual server to auto-run a script on
startup
- the script receives command line arguments describing how to connect back to the server. You can use the external script-on-startup to load a static dataset or to notify other infrastructure about new server availability
- you can configure each virtual server to auto-run a script on
startup
- improved per-network ACL support
- each virtual network can be configured as one or more of: read, write, admin, stats
- plus overall stability and resiliency improvements to both Carrier Cache and Carrier DB
Also in July, I started a series of AI themed articles (AI how it exists today, AI how it should exist in the future, and which organization have any chance of achieving long-term AI goals), but didn’t get around to finishing it. There’s already too much AI noise in the world it wouldn’t have made a difference.
August
Released This is Not LinkedIn as my beachhead for a linkedin replacement because linkedin is the worst and it’s run by a bunch of egotistical awful people.
Also spent a lot of time developing the best representation of a person’s job history described as nested JSON fields, but my writeup and spec for it isn’t out yet (though, This is Not LinkedIn uses it to describe your life which you can view as JSON after you create your resume).
September
Minor contributions from April mentioned in zig release notes for September
October
In October, I attempted to shut my laptop for the first time in a year (normally it’s connected to external monitors and I don’t move it much), but, uh… my laptop didn’t close. Turns out the battery was bulging up through the keyboard and trackpad area about 5% as well as down (so it wobbled a little on flat surfaces too). Took my MacBook Pro into an Apple Store and they fixed it in-store for free under the extended battery service program with only a two day turnaround. Now my 2015 MacBook Pro has a new battery with 0 usage cycles on it (plus the battery swap includes a new keyboard and new trackpad and new speakers because all of those are glued to the battery).
November
Published The Matt Curve
Published The Matt Curve is Eating The World
Published a guide to un-breaking an APFS file system because macOS crashed once, broke a file system on one of my USB drives, and Apple’s macOS APFS tools don’t have any repair capability at all.
Published Criminals and Children Are We
December
Upgraded outdated dependency in my Let’s Encrypt Automation
Released a Python API for This is Not LinkedIn so you can save your resumes locally, edit them from the command lined, then re-upload them all without visiting This is Not LinkedIn.
Posted a presidential campaign page of what we should be looking for in a leader: Matt 4 President
Released my massively parallel HN site downloader I had written back in July/August
Published Moloch Commutes
Published YIR-2019
Future
here’s to having the world survive another year,