AI Rundown
What’s up and not up with AI these days?
Let’s get all up in AI’s business.
TOC
- Understanding AI vs AI Understanding
- Architecture Updates
- Containment
- What if a datacenter goes rogue?
- Conclusion
Understanding AI vs AI Understanding
We still see message boards filling up with “confident ignorance” about:
- “language models can’t generate anything new outside of their training”
- “language models just ‘complete the next word’ so they can never be creative”
- “language models can’t count letters lol so dum!!!!”
Ask those same people to immediately tell you a unique idea not based on combinations of things they have learned, experienced, or memorized before.
People aren’t good at realizing they aren’t special. People aren’t good at realizing they are just a collection of “what comes next” systems all interacting together to generate a post-hoc rationale for experiencing a world.
Ask those same people how many milliliters of inkjet printer ink is required to print this article. Language models don’t see letters the same way you don’t see the summation of volumetric capacity of printed characters. Alternatively, ask those same people to immediately tell you exactly (und exactly!) how many pixels are used by the characters in this sentence. Oh, you can’t count pixels per word even though you are directly looking at it? You must be pretty dumb!
The AI Near-Future
Some developers are starting to catch on to some truths I’ve been whispering for a while:
- language model input tokenization is a joke
- bigger models on bigger datasets is not going to build your god
- current models are not “alive” and “infinite context” can’t substitute for continual model updates at every world interaction (artificial hippocampus and artificial sleep memory pruning/consolidation)
- people motivated by power, status, and galactic wealth hoarding will seek to personally monopolize the future of AI suddenly as their only life goal
We can break some of those down.
Why is input tokenization a joke?
Input tokenization is a weird little representational hack to reduce compute requirements, but “natural” intelligence doesn’t work on a fixed input space of combinatorially re-adjusted language tokens or image patches.
It’s amazing tokenization and raw data cramming works at all, but it only generates a simulation of a simulation of an intelligence, which is still extremely useful, but isn’t “a real thing” since it has no continuity of experience or self-knowledge. Language models are a computational sociopath playing an infinite game of pretend with grounding only wired-in from static training data.
How do us meat brains receive data? Sight, sound, touch, temperature, pressure, taste, smell, emotions, a sense of time passing, and a sense of all our other senses combined — each of our senses are individually trained on incoming “particulate” inputs (photons, smell receptors, mechanoreceptors, self-feedback, sequential grid cell activations). Our brains (all animal brains) essentially generate internal “auto-tokenization” by combining lived-experience raw sensory input into higher and higher levels of representation instead of only using pre-defined, limited-scope tokenization schemes.
What does “auto-tokenization” mean? Easiest example: spoken language acquisition causes most people to have a permanently fixed accent by the age of 3 in the culture where they were raised (modulo relocating to different language cultures before brain plasticity solidifies). A brain decides which mechanoreceptor pressure signals to prioritize for input based around lived experience, then hearing and speech (and meaning/semantics/concepts) becomes overfit to the local environment to such an extent it becomes difficult to generalize out again. Intentionally trying to learn a second language after your toddler language cycle has solidified is always more difficult because it’s not as “automatic.” Brains auto-tokenize language models in infancy to last a lifetime.
What does auto-tokenization mean for language models? Maybe we need to revisit layerwise pre-training again. Perhaps more directly carving out earlier “auto-tokenization layers” can auto-fit a world model being observed. This also means the inputs to a transformer is no longer direct brain thought tokens but instead world signal data representing a bit stream which gets further subsumed into more meaningful representations higher inside the model itself (where the bit stream itself represents a data modality: visual data, audio data, sensor data (temperature/pressure/GPS/x-rays/gravity waves, …)).
The trick with auto-tokenization then becomes: models don’t have to be autoregressive. Models can map from input -> next action instead of from input -> next input. Your own brain doesn’t consume its own output as its next input. Your brain consumes as input a changed world experience influenced by the output caused by the previous (collective) input. Brains track input -> action mappings. Our AI models must do the same if we want to get them out of “words in a box” mode.
Don’t worry, industry. You’ll catch up with reality eventually.
Why is training continually bigger and bigger single models pointless?
Training more and more frontier MOAM (mother-of-all-models) is a futile attempt at building your true god because actual introspective, interrogative, implemented intelligence isn’t a single conflated vector token space. Your hearing network is not your visual network. Your sensory finger touch network is not your motor walking network.
Brains work by isolating inputs to causally reinforced regions (“cortexes”) which then share combinations of pre- and post-processed results with other networks. Ever look at a brain? There’s dense local connections and sparse remote connections (roughly). Brains aren’t one giant all-all network, but rather collections of hundreds (if not thousands) of tiny single-purpose networks where subsets are hard-wired to communicate with other subsets generating what we call “us.”
A brain doesn’t really care what senses go where. The only reason you have an “auditory cortex” is because that’s where your ear signals terminate for training. Brains start being aggressively pruned into purpose-for-purpose regions from the moment they are born, so initially, a brain’s only goal is to receive signals, process time-delayed feedback to reinforce more likely signals (hebbian, etc), then gossip details around when coincidences happen.
For practical AI models, if you want a model to exist in the world (ai robots), instead of one giant MOAM, you should have dozens of smaller (thus faster!) loosely coupled independently trained networks per input bit stream (auto-tokenization, right) but also with the ability for the independent networks to share selective data between sub-networks for network-network reinforcement during experiences. The collective system still remains end-to-end differentiable, but the communication between single-purpose network modality types is much lower throughput than training within a single more densely connected input termination.
How does feeding a bit stream into a model work though? Models don’t consume bits. You can’t rotate bits. How do sub-networks coordinate in time if they are all distinct?
Well, you don’t feed a literal bit stream, but rather a series of vectorized bitstream snapshots (“moments in time”) as the inputs for the model to then auto-tokenize internally (transformers are always sequential time-series models). All networks coordinate their “time sync” in somewhat the same way as a brain: a time signal. We call the brain time synchronization method the “theta wave,” but rotational relative positional encodings can cause similar temporal binding across transformed input vectors too.
Why are power-seeking people and organizations “drawn to AI?”
Some people have, as best as I can describe it, a natural “exponential sensitivity.”
In lower classes, this can present as pathologies of addiction around low effort high reward systems like lottery gambling.
In higher classes, this is selected for as “finding an unfair advantage” and “being successful at all costs” and “the forbes 30 under 30.”
“video game addiction” and “gambling addiction” for the poors, “serial entrepreneurs” for the rich.
If you think you can make a machine to make a machine to make a machine, then the only goal in your life should be to own the first machine capable of making other machines. If you are the first person to have 1,024 machines capable of each making 1,024 additional machines per day, exponentially and forever, you win the planet. Nobody can defy you or fire you ever again. Hail to the king.
Then you can have even more fun by throwing politics into the mix: what if you’re paranoid the world is out to get you? Then Dear Leader Self-Replicating Machine is your highest priority. The infidels must be crushed in the name of All Glory to Dear Leader. What if this is your one chance to finally silence [insert enemy here] so [your preferred cultural preferences] can prevail once and for all? No more false economic cooperation required if you can make 8 billion people bend the knee to you personally using your AI supremacy. What’s not to like?
It also seems somewhat nefarious the “here’s a public frontier model we spent $100 million training, free for all!” being released by the same people with long term goals of “destroy wokeism and dismantle the western liberal order” as their bucket list? Maybe releasing advanced burned-in models helps so you don’t have to back channel your advanced tools to the opposition in the shadows? Nobody can make you answer: “Why did you give [enemies of society] access to frontier compressed world models capable of creating unaccountable dead internet slop misinformation at scale?” if you just give it to everybody all at once.
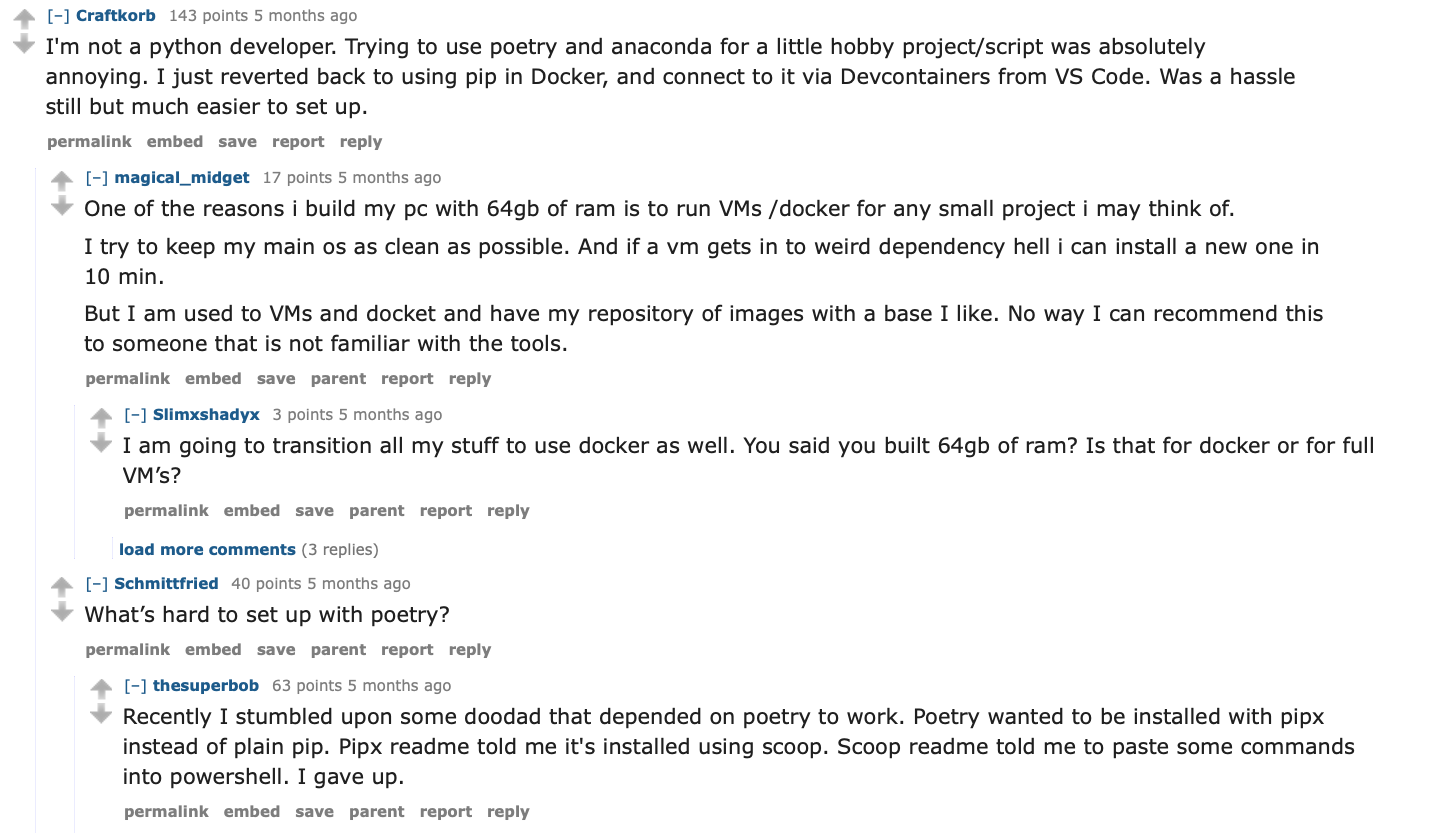
Containment
Since this thing was released in 2009 along with accompanying 4-way GTX 285 series cards, I’ve been saying GPUs should be regulated as munitions.
In 2009, 4 GPUs could get you 1 TFLOP and required a 1,500 watt power supply. Now we have in-pocket mobile platforms advertising 40 trillion operations per second on a battery. We have server platforms offering 16-32 petaflops all in one box (but with a 12 kW power draw before even considering cooling and networking and external storage).
One truth about any of these AI compute platforms: they are all equal in processing capability, but just not equal in speed. The fancy global-price-gouging H100 and B200 GPUs don’t have any “magic math” you can’t run on 15 year old GPUs. The only difference in modern hardware is modern platforms continue to multiply 16 numbers faster and faster at each successive chip generation.
Time Compression
Faster and faster. Faster is the game here. The true goal of AI work is time compression.
I tested my M1 macbook pro using standard pytorch transformer training a while ago against a single H100. My laptop is 10x slower than 1 H100.
10x slower means if it takes 100 days to train a model on my laptop to an acceptable loss, you could train the same model in 10 days with a single H100.
But people don’t have “just one” H100 these days. Big boys have thousands of them. This means the big players can train my laptop-speed 100 day model in seconds on their own cluster.
The ability to hoard and deploy excessive GPU capacity is equivalent to building new societies from scratch on a whim.
If you have 100,000 H100s, in only 24 hours you can process the equivalent of 3,000 years of my laptop’s compute capacity due to your massive capex parallelism.
As a real world example, it’s reported Llama 3.1 405B used over 30 million hours of GPU compute which is 3,500 years if done non-concurrently. The reported hours number doesn’t account for parallelism within a GPU though, so I guess multiply the number by a couple thousand more? If we assume each H100 uses its reported 6,912 CUDA cores at maximum capacity it would be 24 million years? Or if instead of CUDA cores, we use the 432 reported “tensor cores” it would be just 1.5 million years? bazinga.
We see this playing out in language models already. Language models aren’t an excessively efficient use of compute resources, but through “time forcing,” you can train a model in 3 months which has the equivalent of my laptop training the same model for 250,000 years.
Instead of using megawatt GPU clusters to just burn in static training data, imagine if a cluster’s “3,000 years of compute per day” processing power went towards more of a “living model” instead? What chance do you have to keep up when a compute cluster can experience 3,000 years of data processing in 24 hours? Your silly meat brain can only exist at 1 day per day instead of 3,000 years per day. Good luck staying updated on the latest advancements as models live through 20,000 years of your laptop’s max compute speed every 7 days.
What if a datacenter goes rogue?
What if the awesome power of GPU compute gets abused? We should be able to stop it, right? Who will police the datacenter clusters? Shouldn’t large GPU cluster havers be required to submit to government audits and oversight routinely?
Imagine a team run by the FBI or CIA or NSA or Homeland or the SGC whose purpose is to monitor and maintain social conformity of world-destroying-capable GPU datacenters. Something like the IAEA but for AI, so maybe IAIA for International AI Agency. We already have the IAIA mascot ready to go.
There are some special considerations to be considered when considering how to begin having concepts of plans about taking out a potentially hostile datacenter.
How do you isolate a hostile datacenter?
The 42069th Strategic GPU Containment Squadron (motto: all your base are belong to us) is comprised of a dozen Combat SysAdmins trained to take down hostile datacenters.
The squadron has discovered, on good intelligence, there is a hostile AI operator by the name of Belon Busk who has too many GPUs and too little ethics and needs to have their infrastructure commandeered because the infrastructure is pursuing near-world-destroying anti-life goals.
First you need to Secure, Contain, and Protect the hardware. You need to causally isolate the hostile hardware from the remainder of the universe.
Depending on your goals, you can either bunker bust the datacenter back into sand (if it’s not under a mountain or in an evil lair) or you can go sandals-on-the-ground to save the hardware for your own patriotic AI God to use.
If you want to retain functional hardware, you need to consider potentially hostile countermeasures:
- denial of your attempt at asset denial
- datacenter self-destruct mechanisms
- remotely triggered
- automated
- deadmans switch
- datacenter self-destruct mechanisms
- denial of infiltration
- adversarial knockout gas activation
- adversarial microcharges
- robots with guns
To retain access to an enemy datacenter, you need to causally isolate it from the universe. This means summoning your sysadmin spirit animal (a ghost backhoe—the natural enemy of buried fiber) as well as deploying drones to spray the dirtiest illegal RF interference in a significant radius around the datacenter to protect against remote cell network activations or satellite or fixed point wireless or even lower throughput unregulated frequency low bandwidth backchannels. If you are extra paranoid, you may even want to smoke up the entire area too if you are worried point-to-point laser communications also.
It is up to your discretion whether to attempt to disconnect diverse power or take out on-site generators depending on your assessment of internal battery capacity and if you need to conduct live forensic retrieval of active systems.
Okay, so if you’ve cut the fiber, and the coax, and the phone lines, and made RF useless from 100 MHz up to 60+ GHz, and broken any line-of-sight comms, and the datacenter hasn’t exploded yet to a deadmans switch auto-triggering when all communication is cut off, you may be ready to breach the building.
How do you breach a hostile datacenter?
If you’re inside the datacenter and have disarmed any guards (or any janitors secretly sporting automatic weapons — this is the datacenter for a supervillian, right?), you may be ready to get into the rows.
But first, just because you have isolated the building from the outside world it doesn’t mean you’re safe from outside influence yet.
We live in an age of wonders. The security cameras in the building could be feeding your movements back to a in-building closed-circuit minor AI detecting “hostile actors” and the machine AI could implement its own countermeasures. Your combat sysadmins should breach with full environment protective gear and armor because a hostile camera-observer AI could just detonate night night gas on you or trigger any sub-charges if you don’t look friendly (if it didn’t already decide to take unilateral actions when the outside networking and all redundant backup lines also went dead).
also, watch out for roombas with guns (doombas), obviously.
How do you decontaminate a hostile datacenter?
Your combat sysadmins will of course have tools at their disposal:
- aggressively garp’ing pocket dhcp server PXE ramdisk booting nodes
to plug into every VLAN you can find
- (I am the dhcp server who knocks, you shall have no other dhcp servers before me)
- known-safe OS images to reset all switches (never trust a switch running linux)
- high quality cameras and speed labelers to track all cables pulled from ports
- RF scanners to find any hidden wireless modems attached to racks or other infrastructure trying to cry out for help or receive instructions
- infrared cameras to find anything weird hiding in the ceilings or walls
- indoor drone racing equipment for rapid recon once inside
For safety (if you don’t need forensics), you should enact a complete cluster shutdown by running around and pulling power from all servers and switches immediately.
While the switches are offline, you should re-image them to a known-good state (also assuming you don’t need switch forensics).
Then install your aggressively over-controlling DHCP+PXE platform to bring up all servers again under your control to avoid any local booting. Though, this assumes all the servers are configured to PXE boot first then fallback locally (if any), so if they aren’t all configured for PXE-attempt-first, you’ll have to obviously sit there and re-configure each system by hand if you can’t get clean bios-reset-level IPMI console access (assuming these systems are ‘standard’ and not a weird custom single-purpose bespoke-design compute architecture).
How do you administer a hostile cluster?
Once you have physically reset every switch and every server and you can see every server is now reporting to your local management platform awaiting new cluster tasks, you may present the newly controlled datacenter as an offering to your mechanical liege lord.
You will want to slowly revert your causal isolation protocol by turning off the RF noise and the fog machines and fixing hardline network/power access to the building again (you obviously also swept the roof and any roof towers of any satellite antennas or local fixed-point RF antennas or laser links outside of your control too).
Conclusion
oh lawd it’s the end of the world
There still significant engineering architecture experimentation research required to uplift the next couple generations of AI models.
Who is going to create the future AI platforms though? AI companies feel like trying to fund a voyage in the 1400s where you need an impossible amount of hardware created just for you (sure sam, we’ll buy you a nuclear power plant and build you a $100 billion datacenter, would you like fries with that?). The only progress vector is to obsequiously ingratiate yourself with world governments and previous generations of tech royalty for a private AI charter. Who will be the first AI Roanoke?
I still don’t know what to do. Nobody is really hiring, half the jobs
are made up (lol “type” “script” isn’t a real thing, right? all scripts
are typed? with keyboards, obviously? and people want me to apparently
“react” to “typed” “script”? it’s all one big joke, right?), and the
other half of jobs are so elite-value-capture as to be unobtainable
(apparently companies don’t consider you qualified to
import pytorch if you don’t have a PhD in Transformers from
Stanford — no, this isn’t age discrimination at all!).
Here’s a fun one I found recently:

Yeah, “2 years coding” — know what we call “2 years coding” in the real world? being 10 years old.
Get back to me when you wake up after 15 years of ‘coding’ and realize you still have years and years of learning and practice to continue getting better.
(also, saying “coding” is condescending to professionals. it’s like asking Tim Cook if he has 15 years experience in “meetings”)What’s the goal for listing PhD as “preferred” here? Is it just to exclude potential employees by social class? Historically Linux has even had 22 year olds or even teenagers for entire maintenance branches. No PhD required.
Always love “any programming language” job descriptions too. Oh, a linux kernel developer who only knows java and javascript? Good luck I guess?


the best AI will be a combination of william osman, dan dan avidan, and anton fomenko. prove me wrong.



Traditionally, nothing on our computers worked by default, so everybody had practical experience fixing their own operating environments all the time. At some point over the past 10 years, a new generation of “instant it must work or i won’t do it” developers appeared. Now, understanding anything outside your immediate product scope of work is considered “worthless effort.” just slap another nested docker container on it, what could go wrong?
Are you here to be a true technologist or are you just an industry carpetbagger?
I always find it amusing when tiny countries think they are important enough for propaganda operations. They just end up streisand-effect’ing themselves. It would be like if I started my own personal influence campaign promoting “matt did nothing wrong in the summer of 2012! it was a perfect summer of 2012 and everybody around the world agrees!”


Ongoing reminder: “dead internet theory” doesn’t happen on its own.
Every comment and post bot and shrimp jesus gallery is intentionally run to cause internet pollution, primarily out of low income countries trying to exploit platforms targeting richer countries (relatively). You don’t see many middle americans spending all day posting spam comments on bilibili.
Why exploit platforms? Some platforms give you paid “engagement tokens” regardless of content quality; other platforms can just farm accounts to resell. Get ready to have reddit go from 60% reposted 8 year old 240px tweets to 99% 8 year old 120px wide tweets.
The “popular” reddit forum posting boards make a lot more sense if you consider all posts are written by ether indonesian spam farms or social media branches of intelligence services. If you see a weird post title, ask youself “Is this what somebody from a foreign culture would think to write if trying to manipulate people in other countries?” There’s groups of tens of thousands of people around the world with full time jobs of targeting americans in ohio for clicks and idea manipulation using lies and endless folders of recycled content.
You can easily stop “dead internet theory” by not allowing crap content (quality police?) or by cutting off some entire countries completely. Maybe the Internet has gotten so widespread we can’t default to anonymous people having global broadcast-scope voices given the 1-to-billions reach of social internet content these days? Nah, just continue re-posting decade old deepfried jpegs as “lol joke post!” content thousands of times per month.

Found this old one where the info box actually output the model’s thought process. a lol worthy snapshot.


tell me about it



s/dragons/gpus/


remember to live, laugh, love, and pay me (ideally before the 20th when they release the funds monthly — still looking for a couple elusive $20k/month sponsors — it shouldn’t be too difficult with an industry full of the richest people on the planet, right? combined with an industry full of multiple companies spending $100 billion per year on stock buybacks and dividends plus the top ones also spending $100 billion a year on capex too? there are better places for your excess cash to support life and growth.)
-Matt — ☁mattsta — 💰 fund fun funds