Quicklist Final
(Still have a short attention span? See graphs at the bottom.)
This describes the third and final major improvement to Redis Quicklist.
Previously On
Recap
- Before Quicklist, Redis Lists had two representations:
- ziplist stored small lists in a solid block of memory. list elements are managed by offset instead of chains of pointers.
- linked list stored large lists with every element in a new node with next/prev/data pointers maintaining the list.
- Linked list required 40 bytes of pointer overhead per list entry. If you store something small (like a timestamp or user ID), the metadata overhead is easily 10x larger than actual data (e.g. a 4 byte timestamp has 40 bytes storage overhead).
- Pointers hurt small data.
- Storing 1 billion 4 byte timestamps is 4 GB data and 40 GB overhead.
- Ziplists exist to remove oppressive pointer overhead.
- ziplists sound great, but the downside is they are sequential blocks
of memory.
- every change to a ziplist invokes a
realloc()- inserting to list head involves copying the entire ziplist down so the new element can fit at the start of the ziplist memory block.
- if a ziplist grows too big, performance drops through the floor
because
realloc()of large objects blows out your fast CPU caches and results in spillage down to a slower cache (“slow,” considering Redis operations should take single digit microseconds to execute).
- every change to a ziplist invokes a
Summary of Recap: Quicklist is a linked list of ziplists. Quicklist combines the memory efficiency of small ziplists with the extensibility of a linked list allowing us to create space-efficient lists of any length.
Visions and Revisions
Initial
The first quicklist version used static ziplist lengths for each interior ziplist. The result graphs showed us how reduction in pointer overhead quickly reduces memory usage.
Downside of initial approach: you must manually configure the ziplist length, but the optimal setting depends on the size of your list elements. It’s not easy to configure properly.
| Benchmark | Before Quicklist | After Quicklist (specify lengths manually) |
|---|---|---|
| 200 lists with 1 million integers | 11.86 GB | 8.9 GB to 1.0 GB (depending on length) |
| 1 list with 23 million dictionary words | 1.67 GB | 1.4 GB to 0.300 GB (depending on length) |
| 3,000 lists with 800 2.5 KB JSON documents | 8.12 GB | 8.1 GB to 7.8 GB (depending on length) |
Second
The second quicklist version added dynamic adaptive lengths based on the total byte size of the ziplist.
With ziplists, memory resizing operations dominate performance. If we limit the entire ziplist size to a known-efficient size (8k), we keep performance bounded in the really good and fast range.
Dynamic adaptive ziplists mean you don’t need to do any any manual configuration of your parameters. You get optimal performance3 with no adjustments needed.
The rules for setting Redis Quicklist ziplist sizes are now:
- If configured length is 1 or larger, use that ziplist length, but
also apply a safety maximum size of 8k for any ziplist (rationale).
- elements larger than 8k will exist in their own individual ziplist4.
- If configured length is negative, use dynamic adaptive ziplist
capacity for one of five different size classes:
- Length -1: 4k
- Length -2: 8k
- Length -3: 16k
- Length -4: 32k
- Length -5: 64k
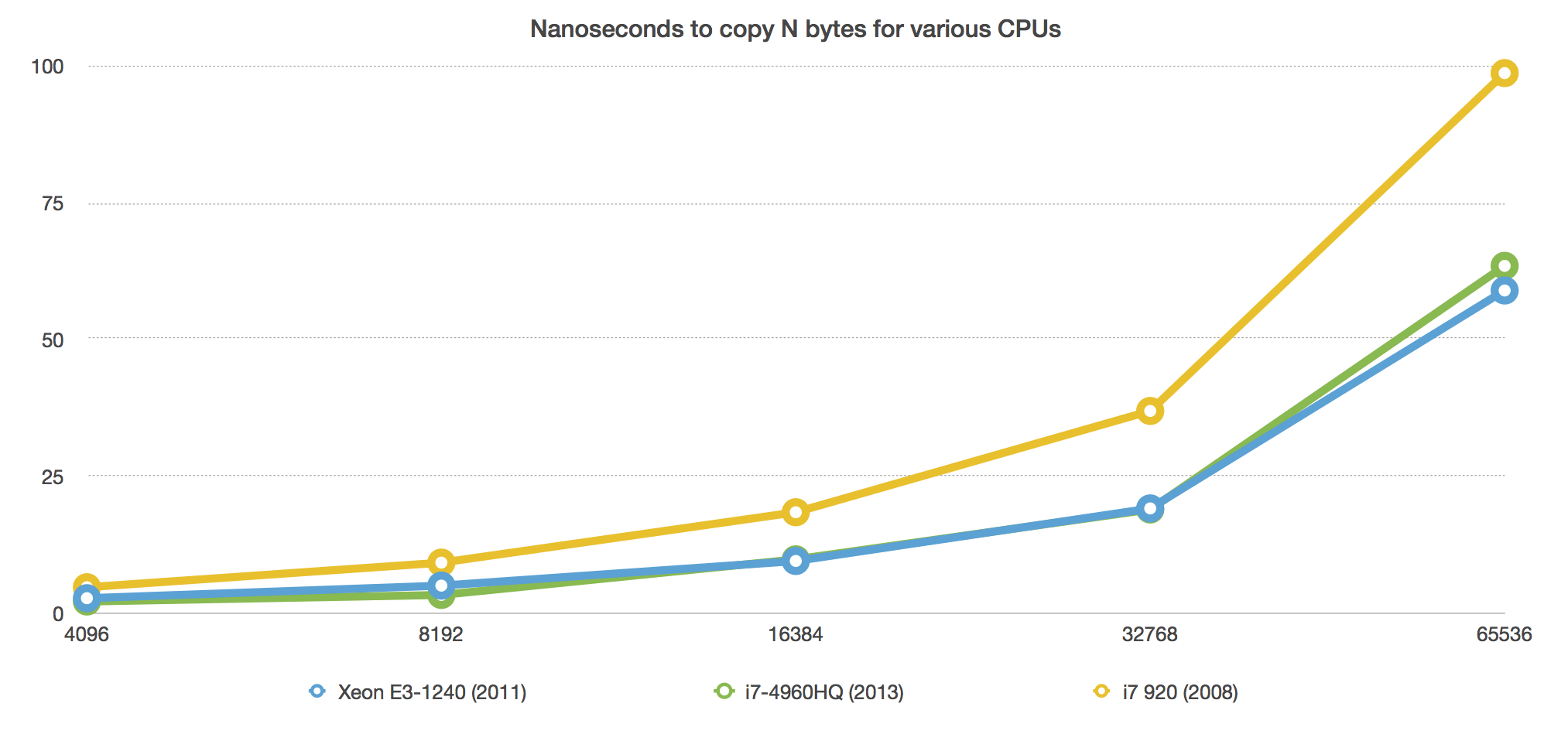
An adaptive ziplist length of -2 (max size 8 KB per ziplist) typically gives the best performance because of this graph:
| Benchmark | Before Quicklist | After Quicklist (dynamic adaptive lengths) |
|---|---|---|
| 200 lists with 1 million integers | 11.86 GB | 0.953 GB |
| 1 list with 23 million dictionary words | 1.67 GB | 0.262 GB |
| 3,000 lists with 800 2.5 KB JSON documents | 8.12 GB | 9.19 GB ([8.15 GB at -4]) |
| 1 list with 10 million 40 byte elements | 1.05 GB | 0.406 GB |
| 1 list with 10 million 1 KB elements | 12.41 GB | 10.98 GB |
Final
ziplists store many elements in one sequential block of memory.
If we’re storing many similar things together, that sounds like a great opportunity to apply compression, doesn’t it?
Each ziplist holds multiple elements, so if your list has homogeneous content, nice compression ratios happen. Plus, since ziplists are already fixed to a maximum small size, (de)compression time doesn’t greatly impact performance.
Since this is a linked list data structure5, we can also make a major performance optimization: We always leave the head and tail ziplists of the quicklist uncompressed. Regular PUSH/POP operations remain fast, it greatly simplifies the implementation if we can assume head/tail is always readable and writeable, and we can compress our inner ziplist nodes (which probably aren’t needed for immediate access anyway) without impacting performance of the most used list operations.
See graphs below for performance comparisons of compressed vs. uncompressed operations.
Besides compression, the final version adds/optimizes:
- saving and restoring large lists from RDB is now 5x to 10x faster than before.
- transferring large lists over the network for replication/clustering
benefits from the same 5x to 10x speed increase.
- also, replication and on-disk storage of large lists will be smaller
since we compress multiple list elements together.
- double also, if your Quicklist is compressed, RDB/replication/migration uses the already compressed ziplists for transfer, so we don’t need to waste time compressing data at save/replicate/migrate time if we’re already compressed.
- also, replication and on-disk storage of large lists will be smaller
since we compress multiple list elements together.
- the Quicklist test code runs over 200,000 test cases covering ranges of ziplist fill levels and ranges of compression options.
DEBUG OBJECTlearned about Quicklists so you can introspect otherwise hidden implementation details (number of ziplists, ziplist fill counts, total uncompressed size to calculate your compression ratios).
Results
Memory Usage
| Benchmark | Before Quicklist | After Quicklist+Compression |
|---|---|---|
| 200 lists with 1 million integers | 11.86 GB | 0.953 GB |
| 1 list with 23 million dictionary words | 1.67 GB | 0.260 GB |
| 3,000 lists with 800 2.5 KB JSON documents | 8.12 GB | 2.36 GB ([1.24 GB at -3]) ([1.05 GB at -4]) |
| 1 list with 10 million 40 byte elements | 1.05 GB | 0.010 GB |
| 1 list with 10 million 1 KB elements | 12.41 GB | 0.219 GB |
Some data layouts can’t be compressed nicely. Our benchmark of 1 million sequential integers doesn’t have anything to compress, so the space saving there is completely from removing pointers. The list of dictionary words doesn’t have much to compress, but it did compress at least a few nodes (262 MB to 260 MB).
The real compression savings happen when you have redundant redundant data. Large elements of human readable text are safe targets for compression.
The last two benchmarks in the table above show levels of
hypercompression because they used redis-benchmark for
testing. For filling data, redis-benchmark just repeats
x over and over again. So, ‘40 byte elements’ is actually
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx 10 million times. You
can see how compression obliterates duplicate memory usage there. The
same goes for the 1k test, except it’s even more xs
(xs? x’s? exs? exes? ex’s? xes?).
Final Performance
Y-Axis: requests per second; no pipeline; all individual commands.
X-Axis: ziplist length parameter given to quicklist. negative numbers are fixed ziplist sizes. positive numbers are manually specified ziplist element counts.
The X-axis marker ORIGINAL is the original Redis Linked List performance (storing one element per linked list node).
The graphs below show us three things:
- original Redis Linked List performance for all operations tested here
- Quicklist performance without compression
- Quicklist performance with compression at various “depth” settings
In all graphs below, the blue line with square markers is uncompressed Quicklist performance.
Quick definition: compression depth — the number of Quicklist nodes from each end of the Quicklist to leave untouched before we start compressing inner nodes.
Example: a depth of 1 means compress every Quicklist node/ziplist except the head and tail of the list. A depth of 2 means never compress head or head->next or tail->prev or tail. A depth of 3 starts compression after head->next->next and before tail->prev->prev, etc.
Depth also lets you avoid compressing small lists. If your Quicklist only ever has 4 ziplist nodes and you set compress depth 2, then the list will never be compressed since depth 2 means “leave 2 nodes from head and 2 nodes from tail uncompressed,” and depth = 2, but depth applies from both ends, so depth = 2 = 4 nodes.
For smallish values (tested at 40 bytes per list entry here), compression has very little performance impact. When using 40 byte values with a max ziplist size of 8k, that’s around 200 individual elements per ziplist. You only pay the extra “compression overhead” cost when a new ziplist gets created (in this case, once every 200 inserts).
For larger values (tested at 1024 bytes per list entry here), compression does have a noticeable performance impact, but Redis is still operating at over 150,000 operations per second for all good values of ziplist size (-2). When using 1024 byte values with a max ziplist size of 8k, that works out to 7 elements per ziplist. In this case, you pay the extra compression overhead once every seven inserts. That’s why the performance is slightly less in the 1024 byte element case.
Notice how the compression depth doesn’t really matter for performance at all. The only reason to use a compression depth larger than 1 is to leave small lists fully uncompressed while automatically compressing larger lists for optimal memory efficiency + performance tradeoffs across all list lengths.
Graphs
40 byte operations
LPUSH 40 bytes
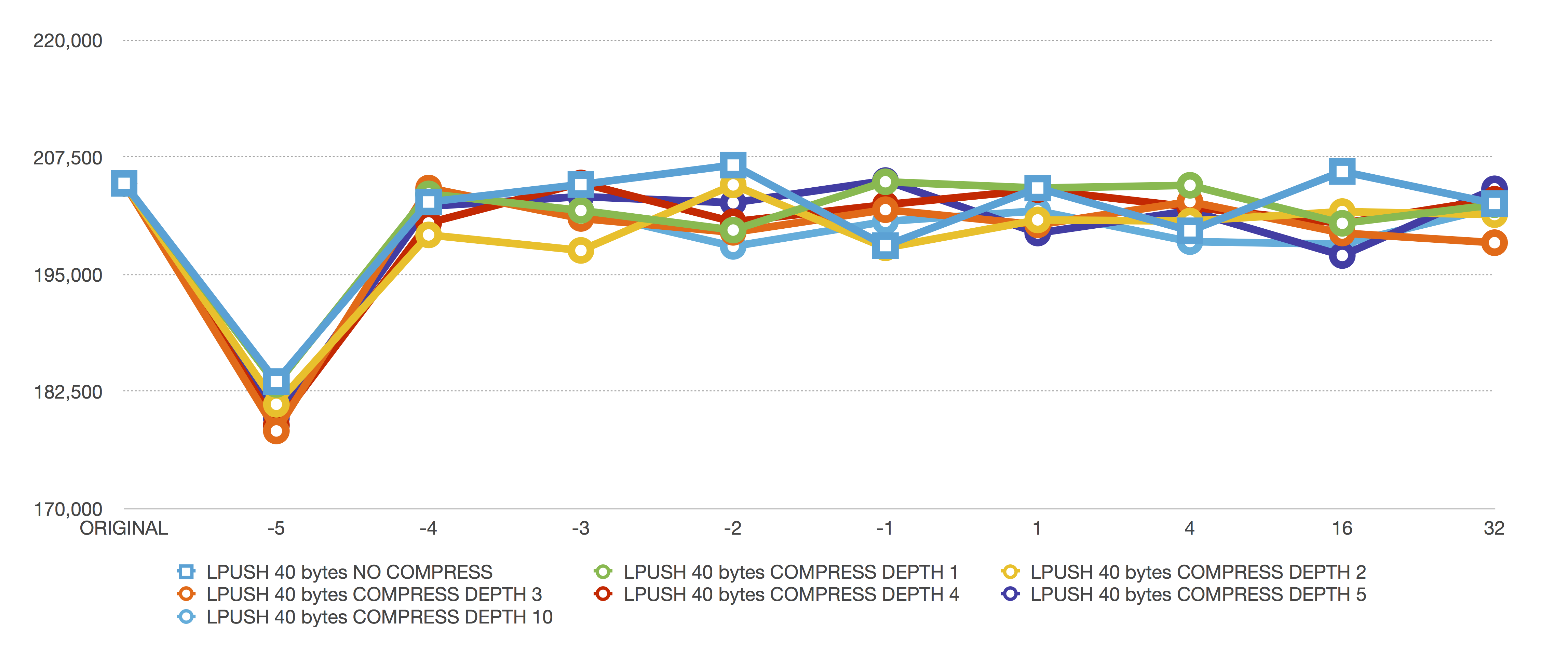
This is an LPUSH, so we are inserting to the head of the list.
When inserting a new ziplist head element, the entire ziplist must be moved down to insert the new element. For reasonable ziplist sizes (-4 = 32k, -3 = 16k, -2 = 8k, …), the copy doesn’t take noticeable time.
The worst ziplist size at -5 (64k), needs to potentially move 64k for an insert. Moving 64 KB of memory is not friendly to your L1 cache and noticeably degrades performance—that’s why we now allow ziplist size based on maximum byte size instead of element counts. You can easily easily set a smaller, CPU efficient maximum size instead of trying to manually figure out, measure, and benchmark how many of your list elements stay below ideal total size thresholds.
RPUSH 40 bytes
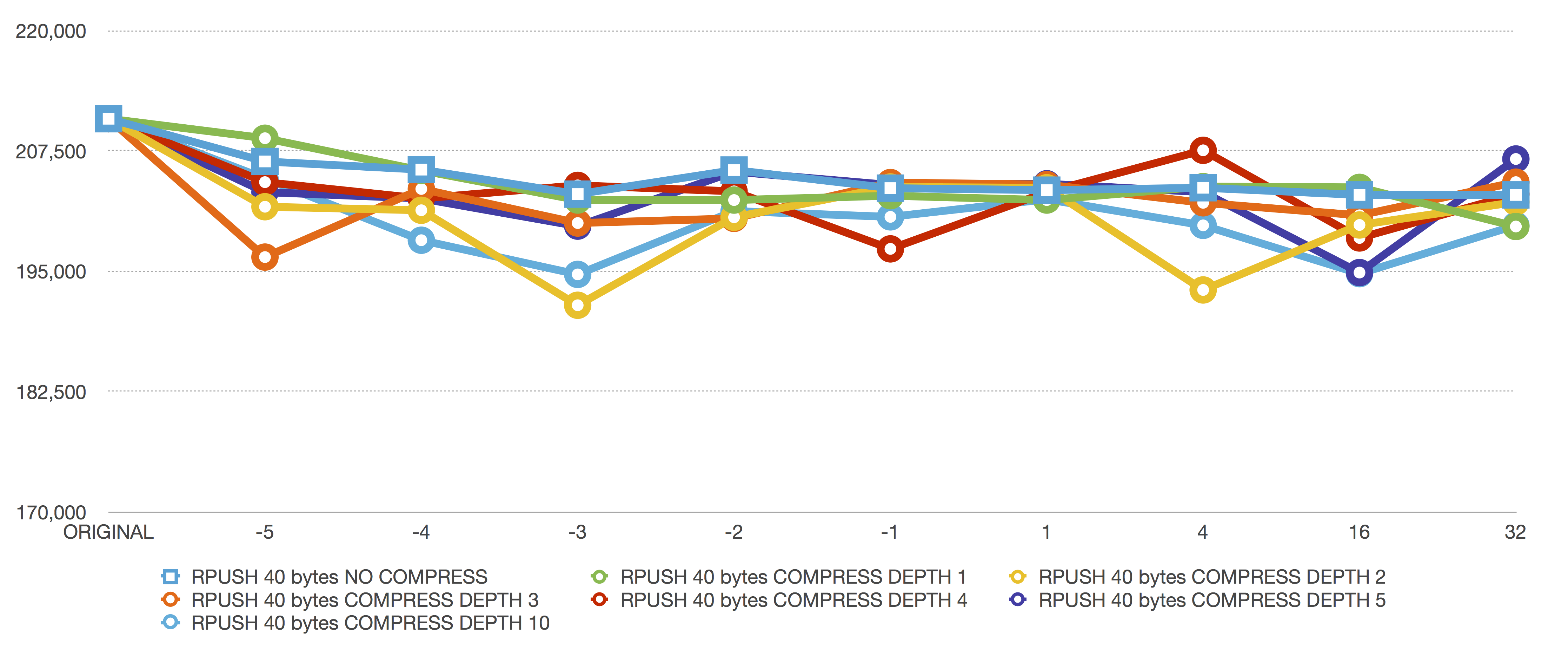
RPUSH is much better than LPUSH for ziplists. RPUSH just needs to extend the size of the existing ziplist. No copying needed6.
LPOP 40 bytes
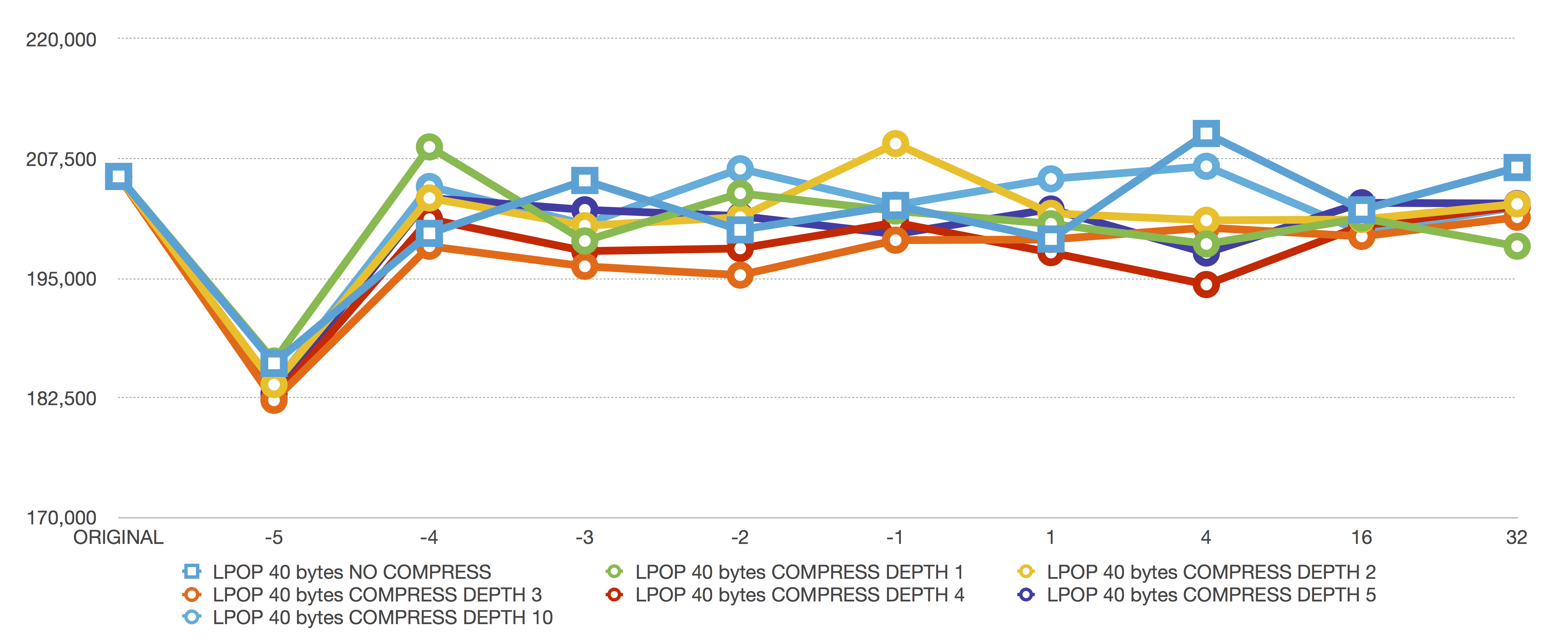
LPOP shows the same performance characteristic as LPUSH because, for LPOP, deleting the head of a ziplist means all the remaining elements must be moved up one position (instead of down one position for an LPUSH). It’s another “copy the entire ziplist” operation.
RPOP 40 bytes
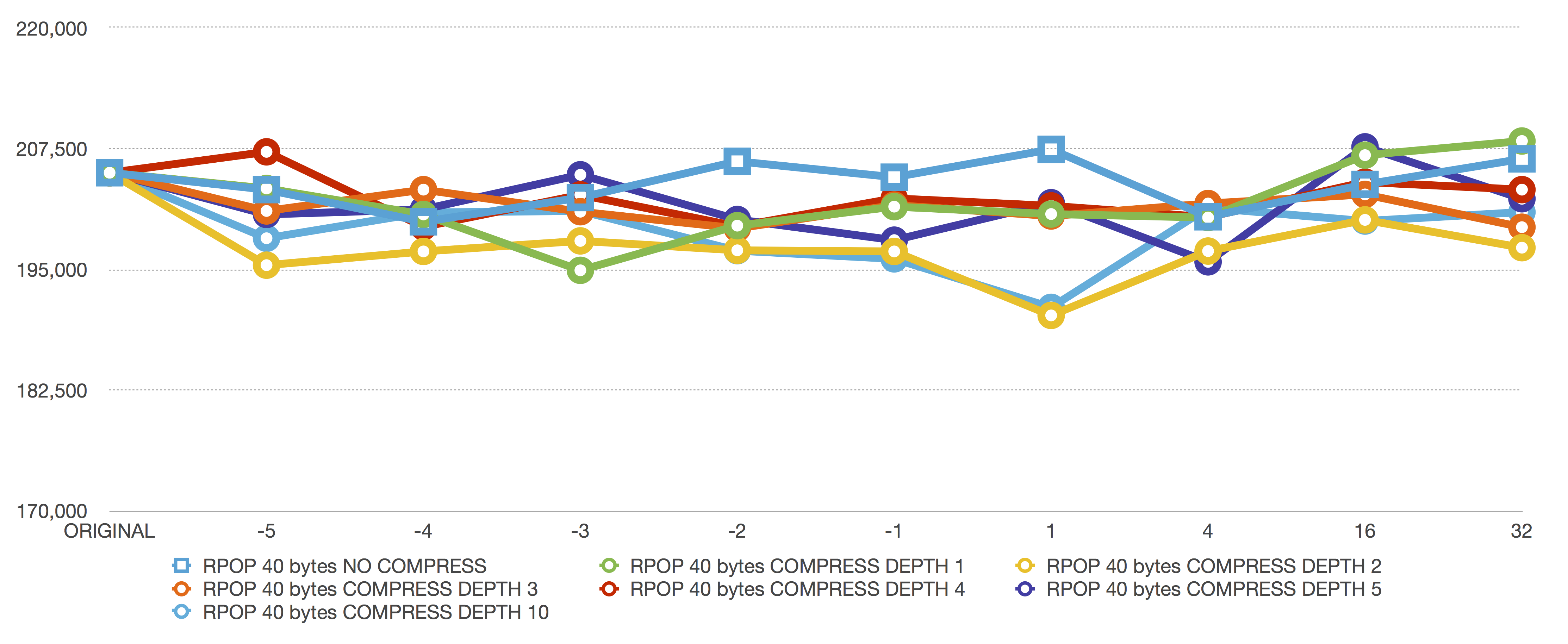
RPOP is the best thing you can do against a ziplist. An RPOP will never reallocate or copy anything because RPOP only deletes the end of the ziplist. No copies needed to delete elements or shrink ziplists.
1024 byte operations
LPUSH 1024 bytes
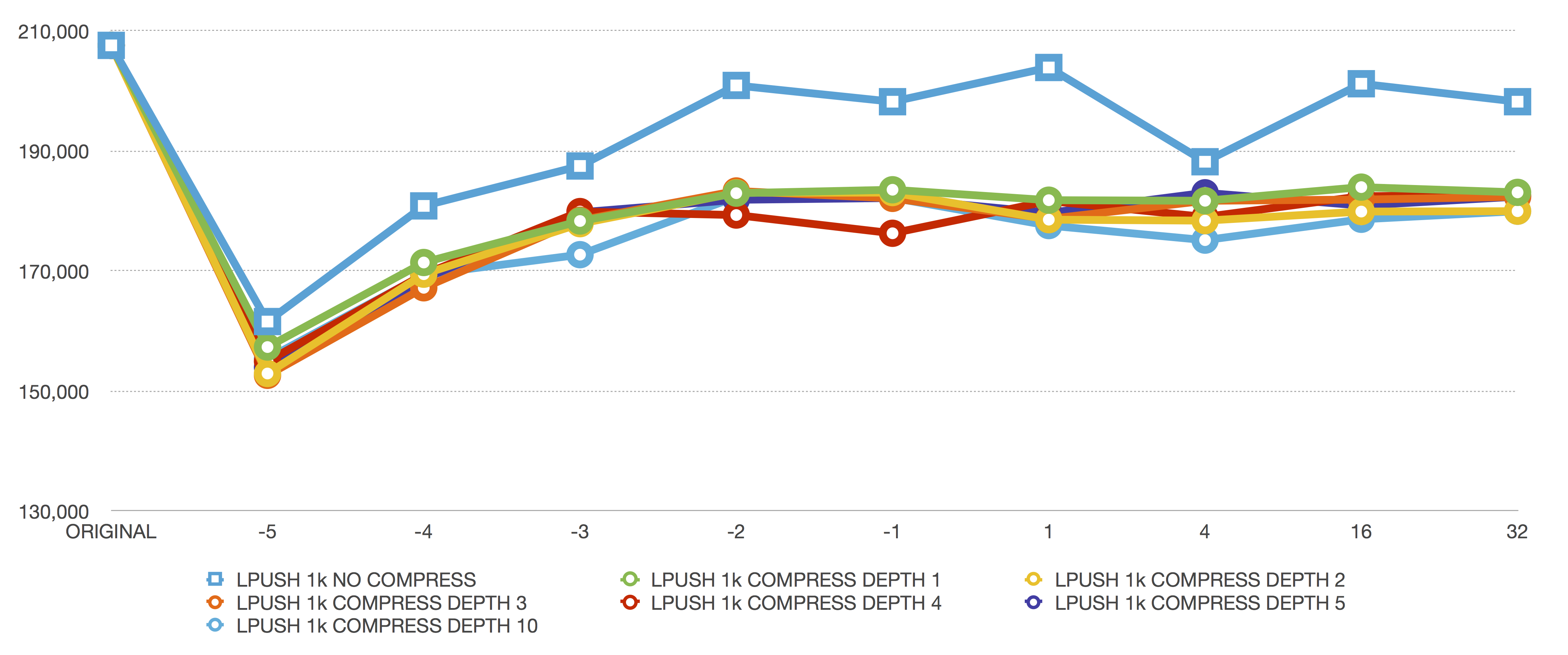
LPUSH of 1024 bytes shows our first major performance difference with compression enabled. At level -2, we go from around 200k to 180k operations per second. But, also at this level, we’re saving a lot more memory because we have larger values to compress together. It’s just a tradeoff. (And, you weren’t actually needing 200,000 requests per second anyway, were you?)
We see the same head-modifying performance characteristics as LPUSH of 40 bytes here too. The -5 level (64 KB) destroys performance, while the smaller levels are all about the same.
RPUSH 1024 bytes
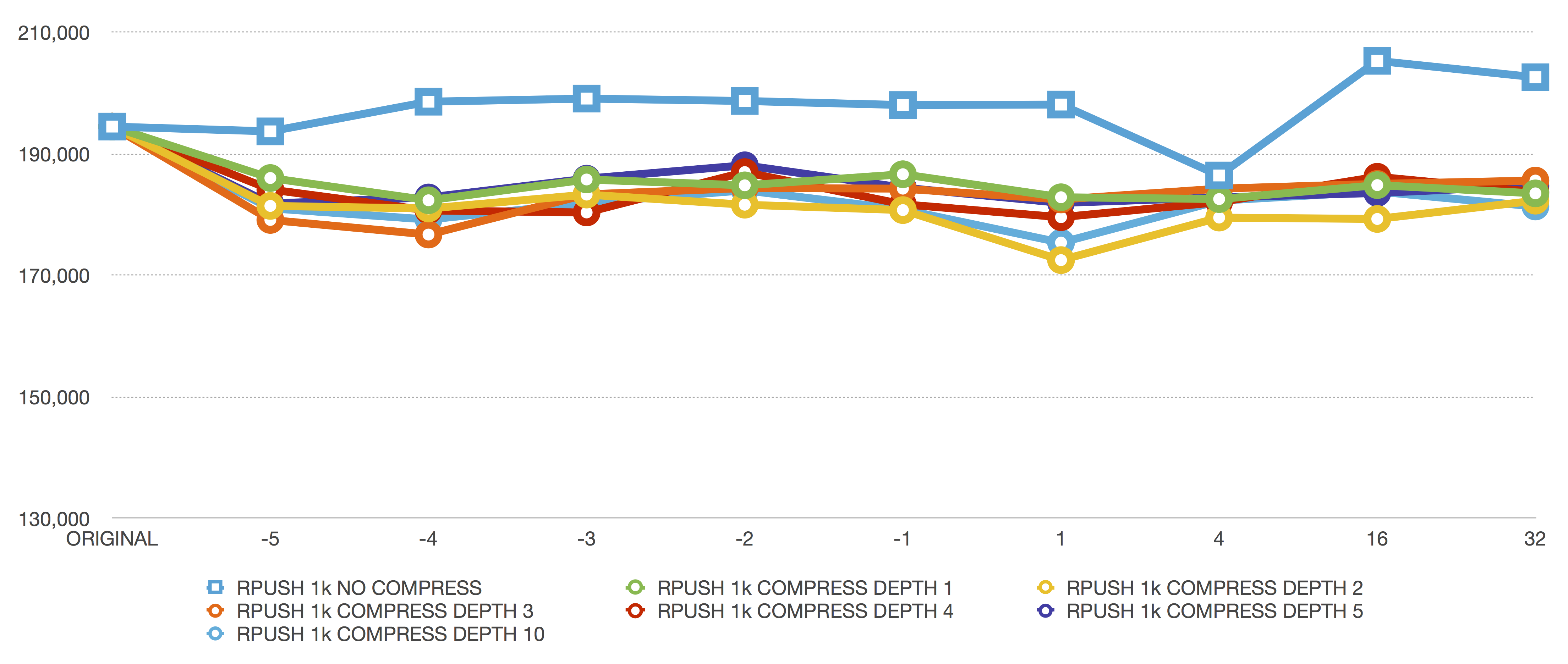
RPUSH is still pretty great here. We have a noticeable performance difference due to compression, but it’s not insurmountable. Going from 200,000 requests per second down to 190,000 while saving 10x the memory is certainly worth it.
LPOP 1024 bytes
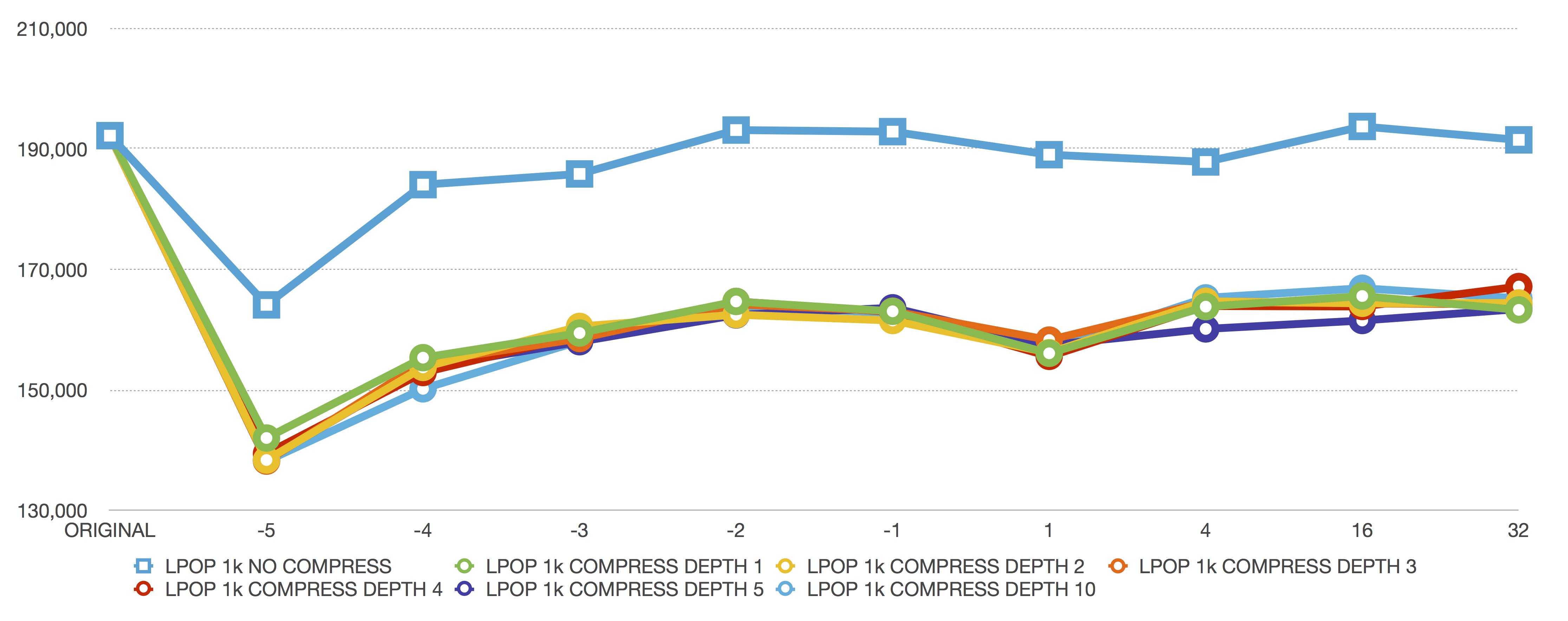
The large-value POP commands are where our results lock down. We see “compress depth” doesn’t matter at all — performance is equivalent with compression enabled.
We also see a performance drop from around 190,000 to 165,000 because, for these large value operations, every 7 POP operations decompress an inner node to prepare it for becoming the head of the list again.
The performance difference here looks almost catastrophic, but the Y-Axis does start at 130,000. Our performance is still pretty great, considering we’re saving expensive RAM costs for slightly lower, but still blazingly fast, data operations.
RPOP 1024 bytes
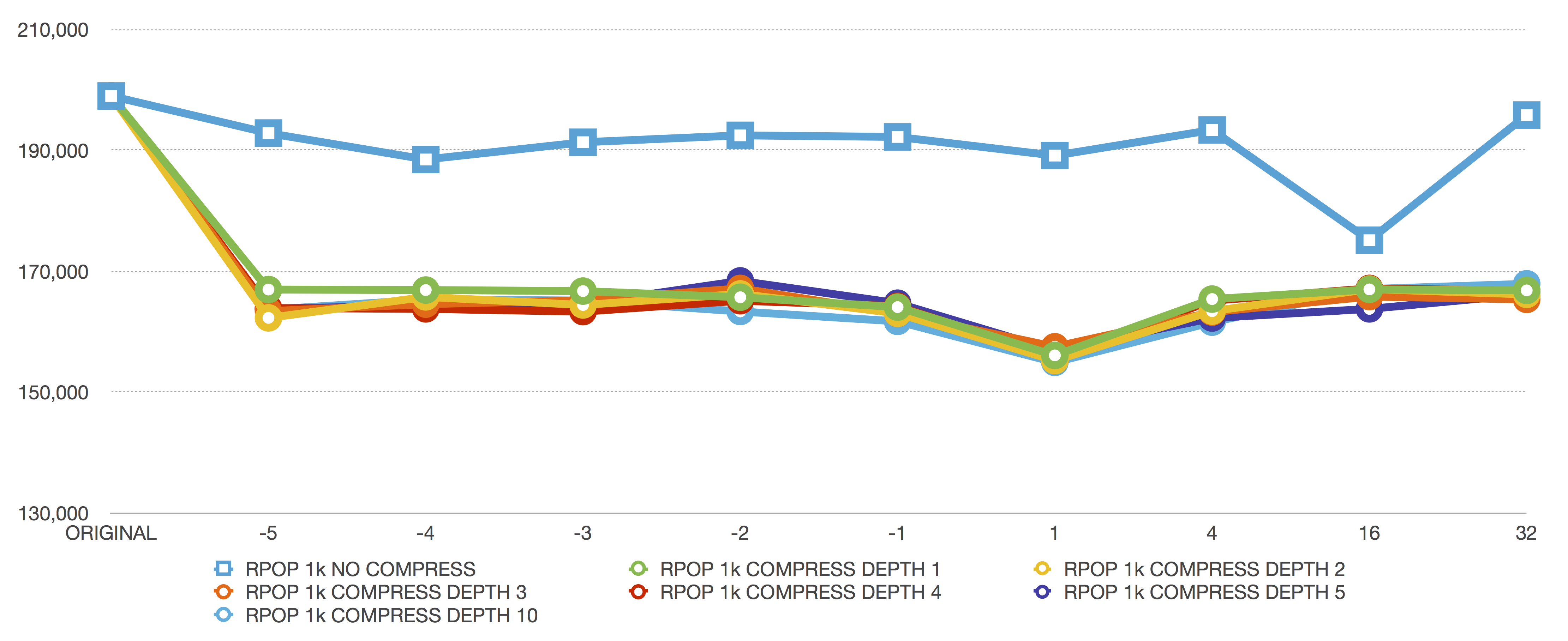
Finally, RPOP of 1k elements looks like LPOP of 1k elements, except the performance is slightly better because RPOP isn’t being burdened with any memory moves.
The strong cluster around -2 also shows we’re at an optimum size for our operatoins.
Conclusion
This is finally done. It may need a tweaks in a few places, but this is the final result.
If some performance properties don’t meet your needs, there are adjustable parameters letting you configure things for custom (read: weird) use cases. For most uses though, the default size-based limits will give you the best performance with no additional configuration attention required (defaults are both high performing and globally applicable? amazing!).
The only decision you need to make: enable compression? The answer depends on a combination of your workload, how amenable your data is to being compressed, and if you prefer to save RAM at the cost of a few requests per second (amortized over all accesses).
That’s it. Please try to break everything (always try to break everything). It’s easier to fix errors in dev/testing before code gets deployed to millions of servers around the world. :)
Code / Discussion / Followup: Redis GitHub Issue #2143
An empty ziplist uses 11 bytes, but as you add elements, the fixed per-element overhead goes down like
11/N byteswhereNis the number of elements in the ziplist. For example, a 300 element ziplist would have a fixed overhead of300/11=0.36 bytesper ziplist entry. (Each entry in a ziplist also has local metadata about the size of the element ranging between 2 and 10 bytes (longer elements have larger length values and use larger integers to store their offsets; small values can fit their lengths in smaller integers)).↩︎An individual Quicklist Node is a 32 byte struct, so the total fixed overhead for list elements becomes: fixed ziplist metadata overhead of 11 bytes + fixed Quicklist Node overhead of 32 bytes. So, if we store 300 elements in one Quicklist Node, the per-element fixed overhead becomes
(11 bytes + 32 bytes)/300 elements=0.14 bytes per element. Each element also has an element-size dependent variable overhead of 2 to 10 bytes depending on the size of the element, but anyway you look at it, that’s much better than the previous 40 bytes per element overhead (2.14 byte overhead to 10.14 byte overhead instead of 40 byte overhead).↩︎We still expose an adjustable size/length configuration option if you want to play with different settings or benchmark various good/bad alternatives.↩︎
We can optimize this further by not encapsulating single-element-only list nodes in a ziplist (kinda pointless to put a single element in a container after all), but that’s left as an exercise for the future.↩︎
Meaning: we don’t expect heavy usage of random access patterns. Linked lists expect you to mostly operate on the head/tail of the list since any other operations incur an O(N) lookup traversal. (Though, with Quicklist, your lookup time is actually O(N/Σ(ziplist lengths before your target node)) because we can skip over entire blocks of elements without needing to traverse them since we maintain ziplist length metadata outside of the ziplist itself.)↩︎
If
realloc()can’t extend the existing allocation in-place, the ziplist is copied to new memory fitting the requested allocation size. So, sometimes the entire ziplist may need to be copied for a size extension, but not always.↩︎