htmx is a erlang
htmx, a disciple of hypermedia, available only in hardcover do not look for alternatives, has been manifesting itself into existence recently (recently: after 10 years of work1) and has finally reached critical mass2.
let’s look into it.
universal server
joe always said his favorite erlang program was the universal server: a process capable of receiving a message to become another server.
universal server pattern
-module(total_server).
-export([test/0]).
universal_server() ->
receive
{become, F} ->
% 'F' is a serialized function which now _becomes_ this process's code.
F()
end.
factorial_server() ->
receive
{From, N} ->
% reply with a factorial answer from the sent 'N'
From ! factorial(N),
% note how this is NOT a universal server:
% the input is ONLY a number and we don't "execute" the input,
% we always just recurse on ourself to serve the next request.
% (also note: this is only an example, so this process is not concurrent)
factorial_server()
end.
% the actual factorial logic
factorial(0) -> 1;
factorial(N) -> N * factorial(N-1).
test() ->
% start the universal server
Pid = spawn(fun universal_server/0),
% send the universal server a message to become a factorial server
Pid ! {become, fun factorial_server/0},
% send the universal server, which is now 'factorial_server/0', a factorial message.
% (also illustrates erlang's built-in bignum support)
Pid ! {self(), 50},
% fetch the result from our mailbox
receive
X -> X
end.This is a simple example, but you can imagine such patterns being useful for distributed online upgrades, self-healing/self-patching systems, etc. Basically, when the ‘replace yourself with the body of a message’ request is one of many inputs to the active process3 you can create arbitrarily complex execution hierarchies, W^X be darned.
running it
Erlang/OTP 26 [erts-14.0.2] [source] [64-bit] [smp:10:10] [jit] [dtrace]
Eshell V14.0.2 (press Ctrl+G to abort, type help(). for help)
1> c(total_server).
{ok,total_server}
2> total_server:test().
30414093201713378043612608166064768844377641568960512000000000000Basically the total_server:test/0 launches
universal_server/0 which accepts a function as a message,
then the server, instead of recursing on itself, it runs the
received serialized function, then the replaced universal server
receives all messages sent to the original server process.
wait how is this htmx related?
oh thanks for reminding me!
There’s a section of the nicely readable htmx docs saying: where an element specifies a load trigger along with a delay, and replaces itself with the response.
See what they did there? replaces itself with the response 🤔
Instead of just sending a request and receiving data, you send a request and receive a “data as code” result with embedded actions (where actions are limited to the surface of features you currently have enabled or disabled as expected).
If you want to run updates via polling, your page can have an initial
fragment for “fetch messages after 1 second then replace this
div with the response” automatically triggered request, and
the response can also return the same automatic trigger logic
where it continues to fetch after the next 1s again too,
all until your server stops returning new “fetch and replace after
1s” fragments to the caller:
<div hx-get="/messages"
hx-trigger="load delay:1s"
hx-swap="outerHTML">
</div>Basically, instead of receiving a JSON update like:
{"data": "muh update", "nextFetch": 1000}where you would also need to implement your own custom parser/mini-VM
to execute actions based on the reply format, the htmx
framework auto-parses results for all htmx-active tags combining maximum
flexibility with minimal busywork overhead (plus, additional controlling
metadata can be included in response headers as well as html
attributes).
takeaway: htmx allows dynamic content replacement, where the content can also issue commands to the current page, including but not limited to also further requesting more remote content to fetch and replace.
You could, if you were weird, pseudo-fork-bomb your site by requesting a fragment which renders two more fragments which continues requesting “fetch -> return 2 more self-fetching fragments” for each instance of the fetch until something breaks; but you can also probably think up more creative uses for APIs capable of returning content capable of using the APIs which caused the original content to be fetched in the first place.
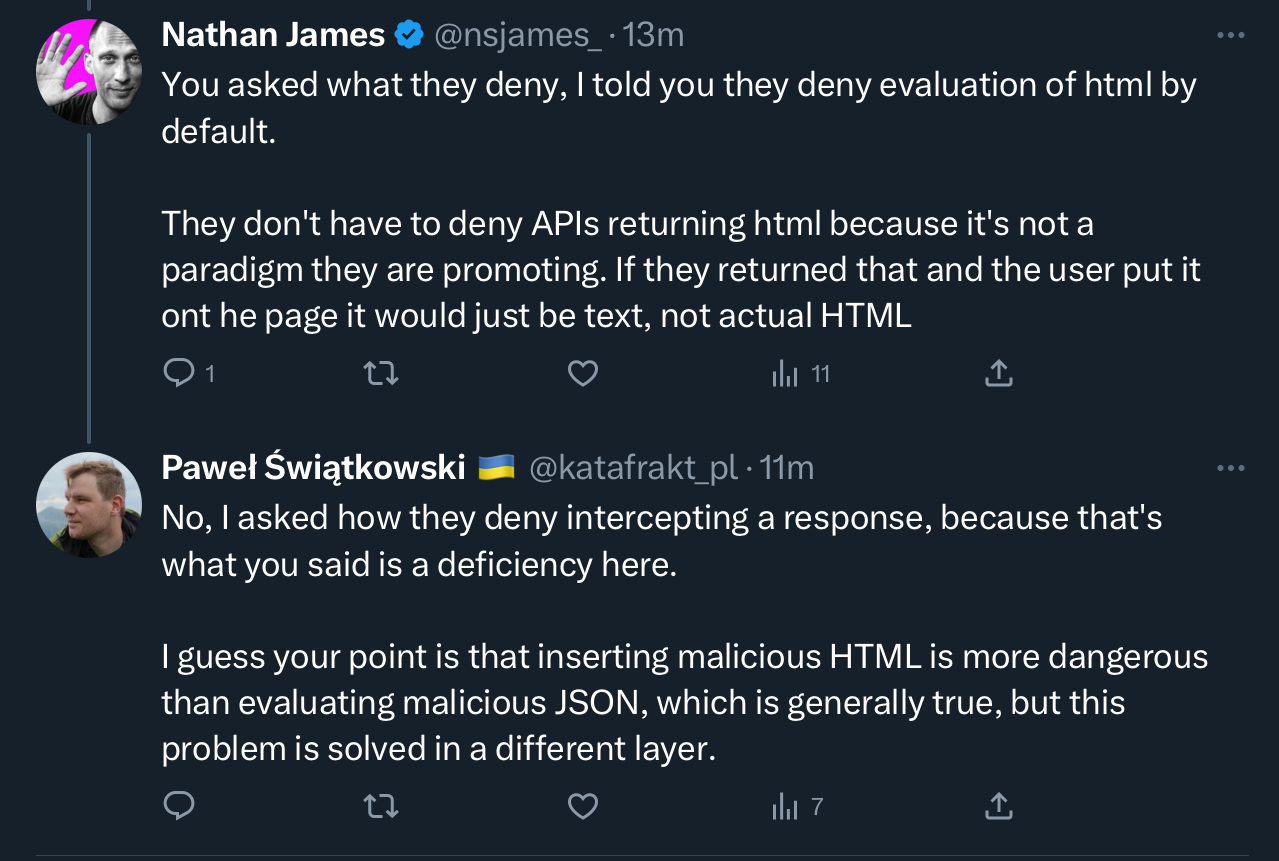
but wut bout muh sekuruty
obviously having any pattern where you consume data then blindly execute based on the result has an attack surface, but security problems are mitigated by two things:
- there is a big ole phat
hx-disableattribute to stop automatic parsing and execution of any children of an element (if you are doing weird things like allowing poorly-sanitized user-generated-content in a page) - you’re (hopefully) not fetching results from random servers; htmx is a single-site, single-organization usage pattern and your site is very likely https/tls-end-to-end verified so wobbly nubbins can’t slip in unauthorized.
smol brain security arguments
there’s an entire genre of online down finger 👇 “developer influencers” who dilute the developer noosphere intelligence center of mass towards marketing drivel, but they can’t help but make online weirdo jerks out of themselves:
OH NO WHAT IF MY APPLICATION ACTS BASED ON RESPONSES FROM MY SERVER????????
2023-07-23
xxxxxxxxxxxxx app worst app (unrelated)
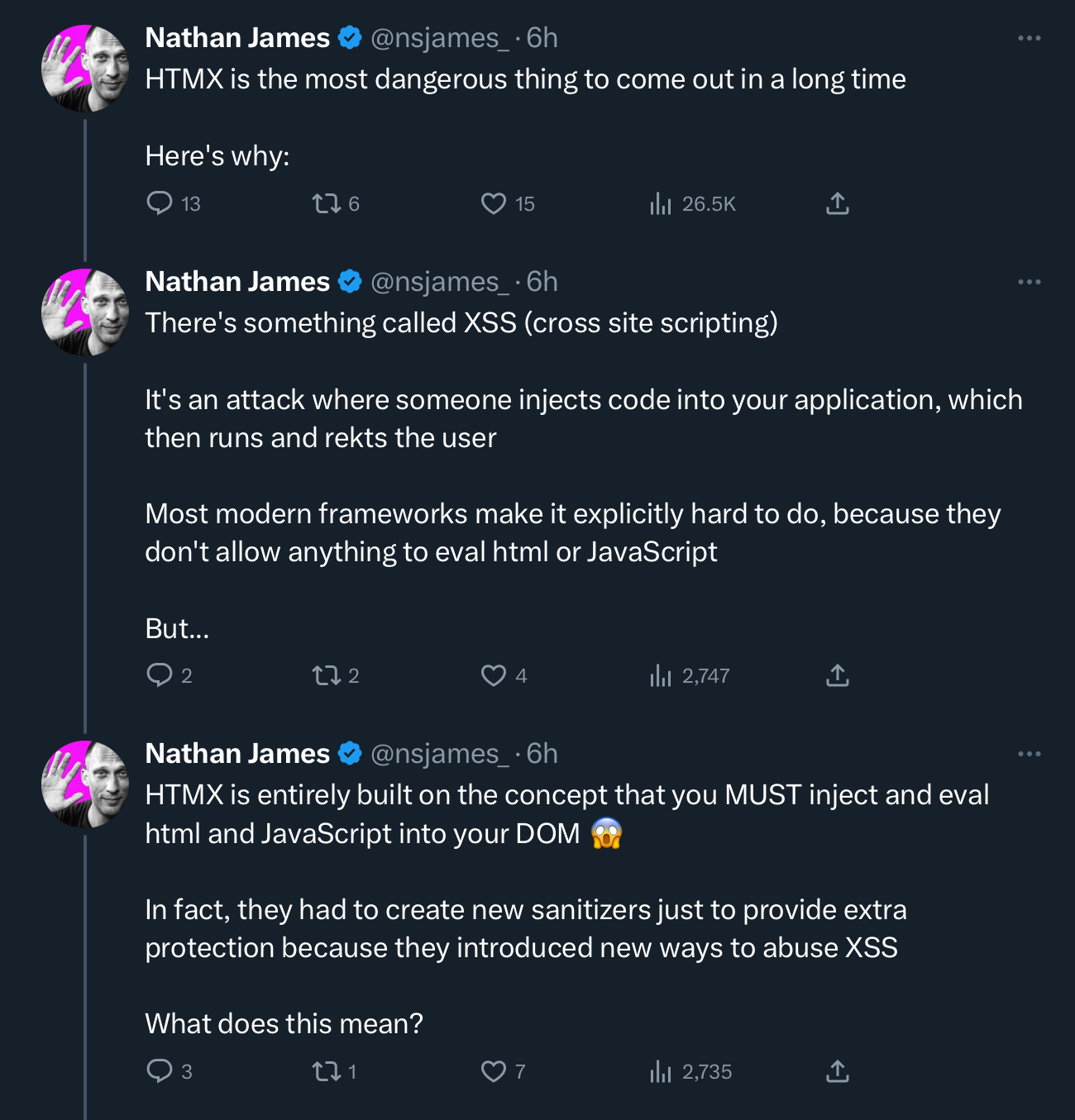
ah yes, the famous XSS coming from your own backend API calls…
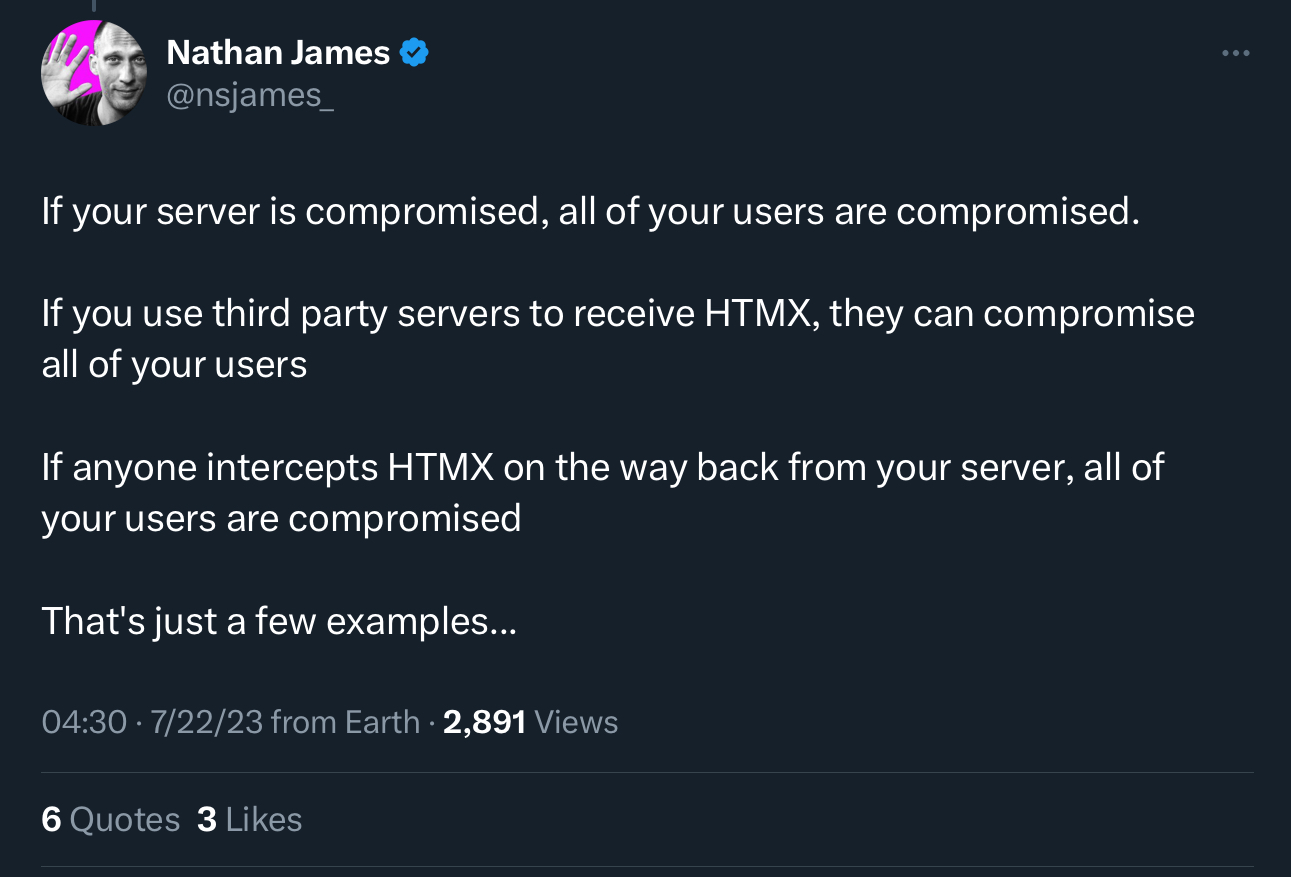
“intercepts” — “on the way back from your server” — sir, it is not 2010 anymore. everybody has free tls certificates these days for exactly the reason specified. so much so, captive portals don’t even work well anymore due to HSTS locks so we need neverssl.com all the time to really check why the system is down
infinite money hack person is giving away free advice on twitter everybody stop working right now.
and remember kids: CODE IS MONEY. the only reason to use computers is MONEY MONEY MONEY
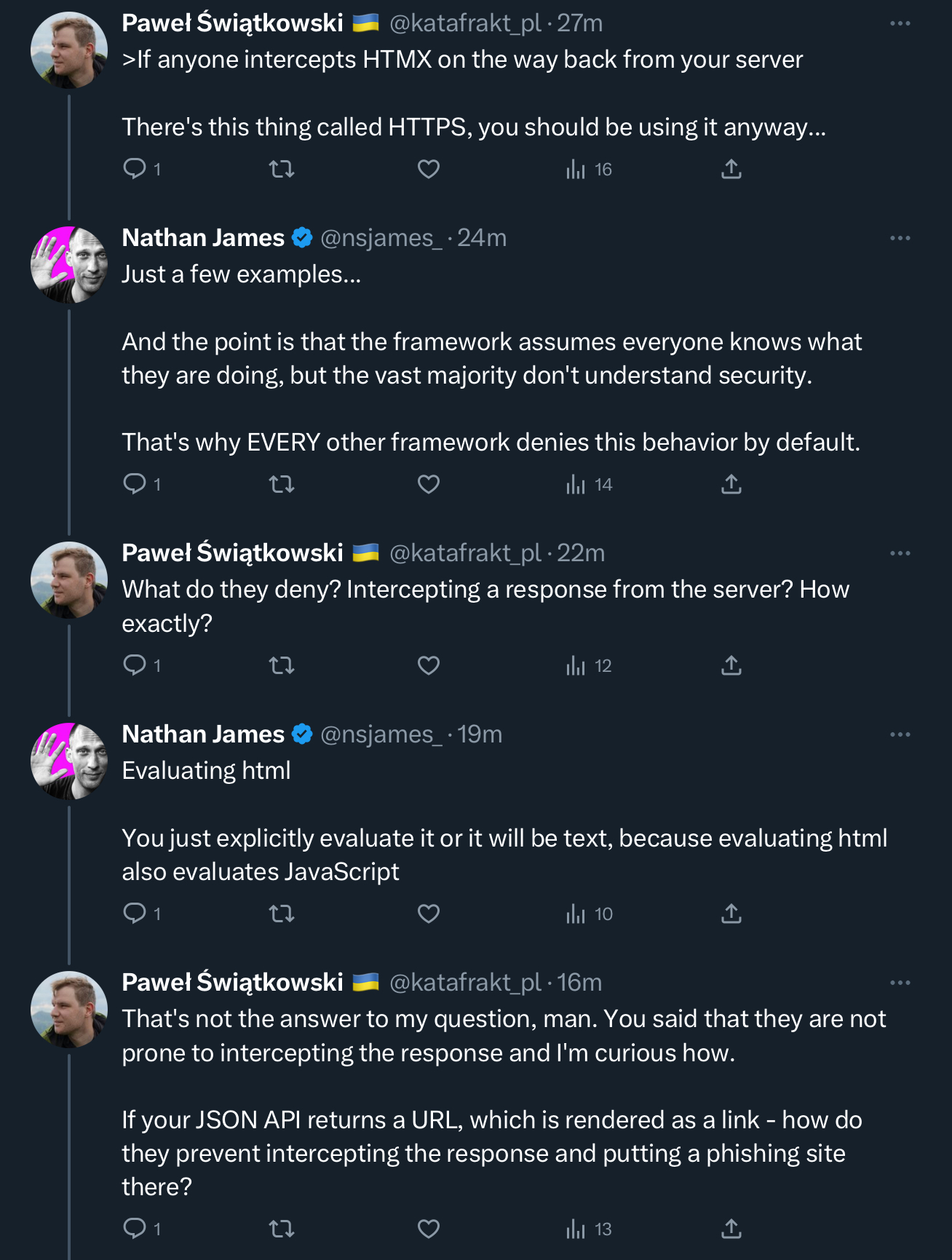
a solid rule of the internet: never disagree with somebody who has those slashed l’s in their name.
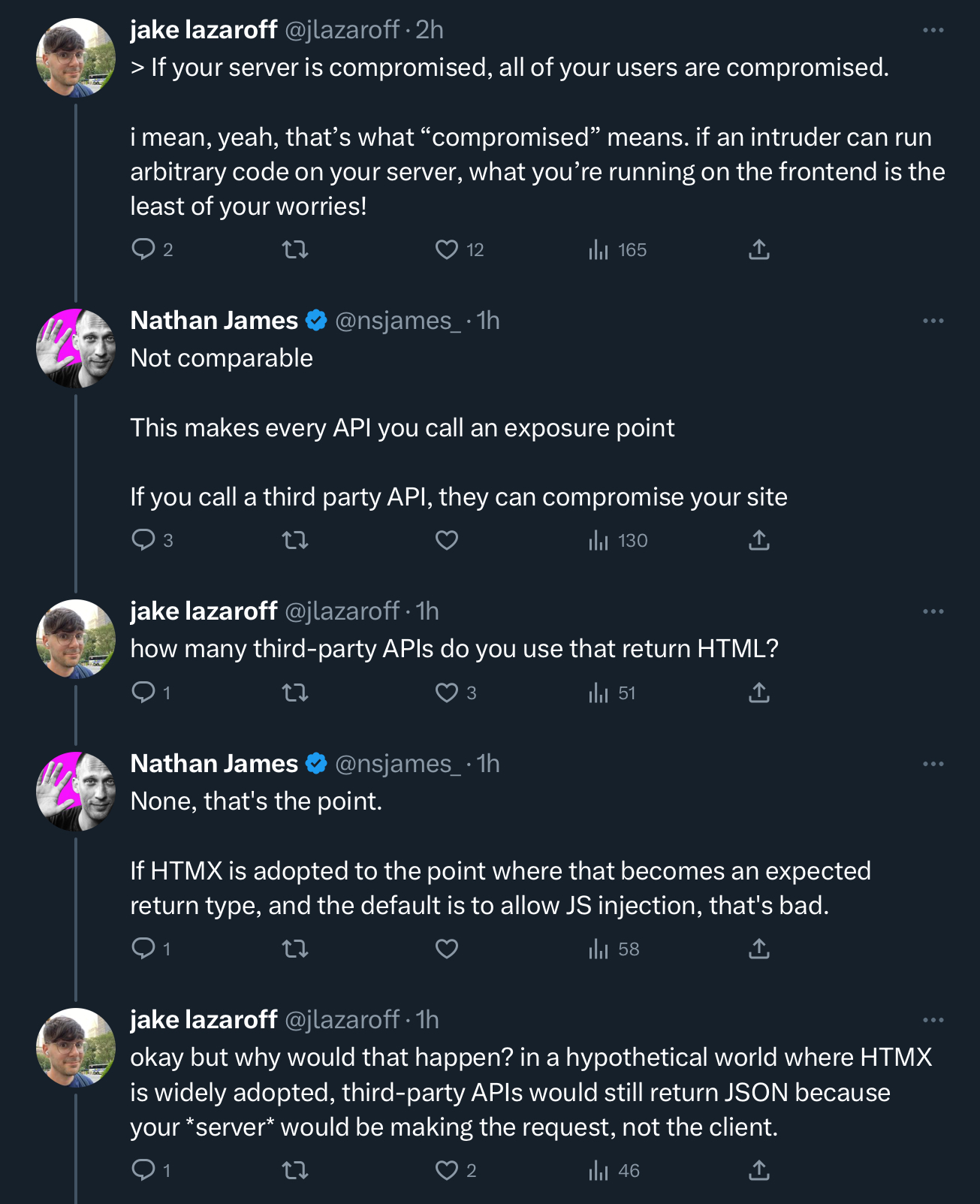
“a third party API can compromise your site” — look at every site contacting 40 external domains using direct javascript injection for unethical-but-marketing-wants-it-so-we-cant-turn-it-off behavioral tracking across the entire universe
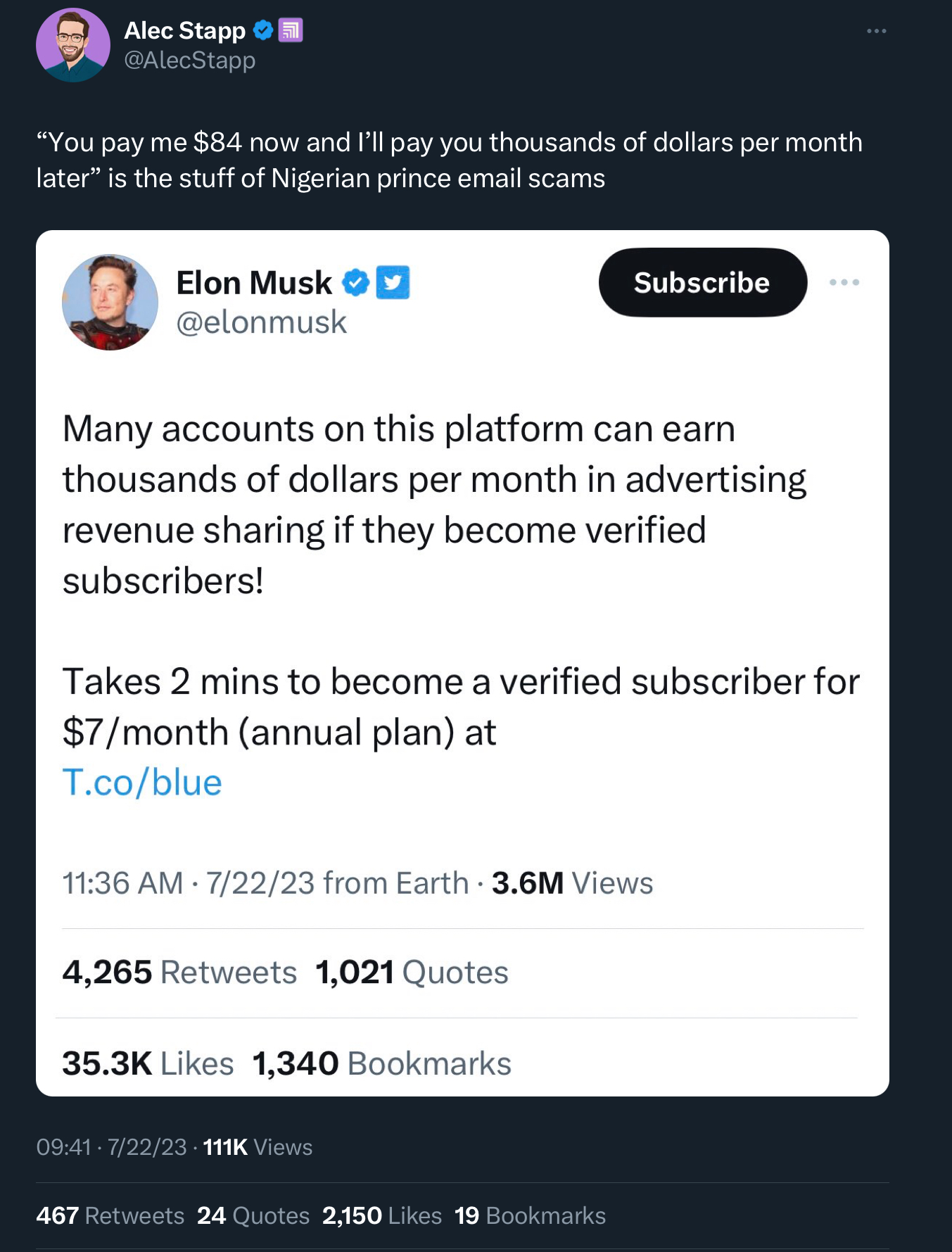
it’s amusing how the rest of us are supposed to just continue pretending the world is normal while K-holed billionaires have no consequences for running outright global scams in public.
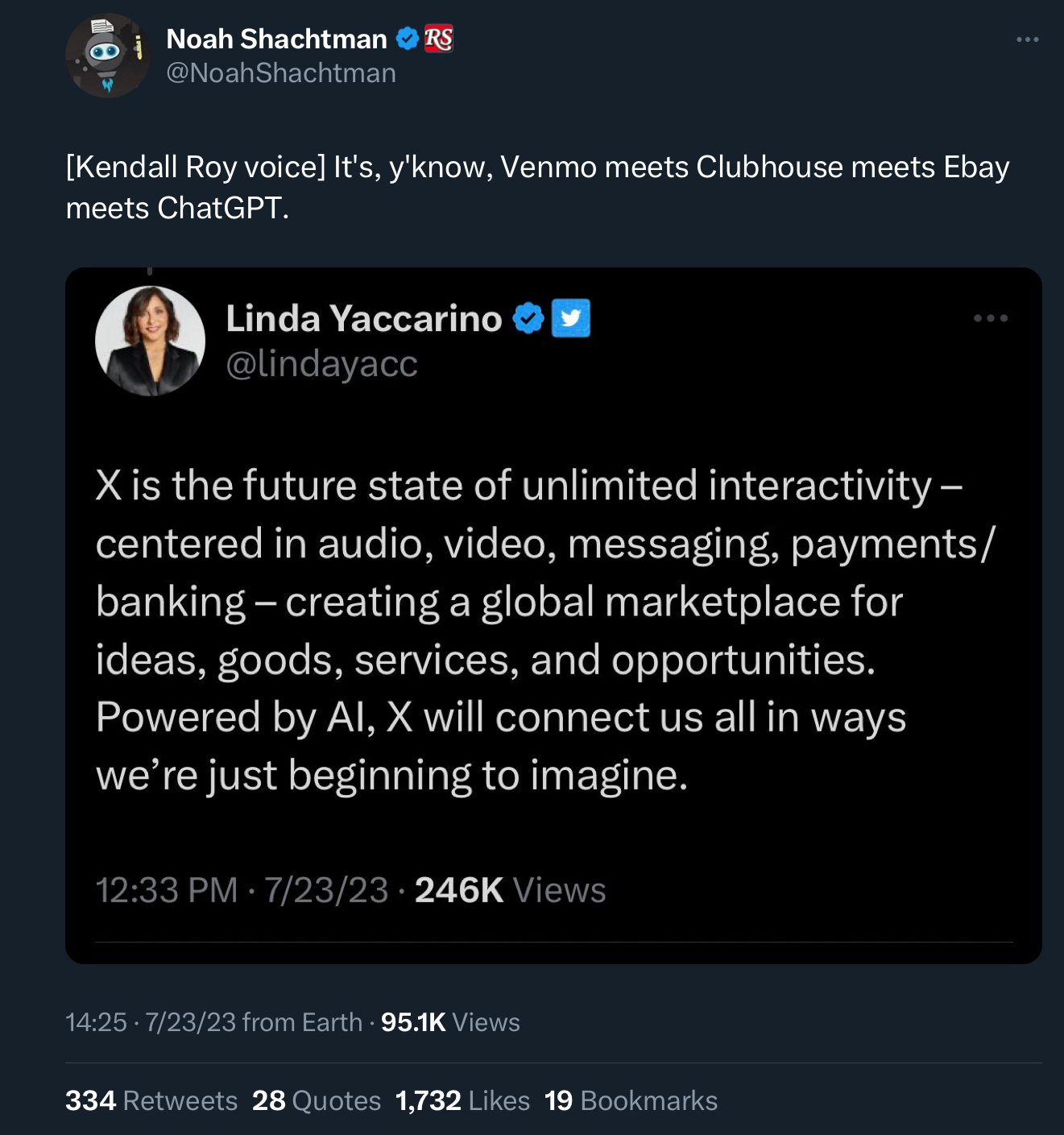
“we’re just beginning to imagine” — maybe because you have the forward looking creative vision of a flushed goldfish?
also these manic ramblings of “we can make a app that does EVERYTHING from FRY EGGS to COLONIZE THE MOON!!!! MY IDEAS ARE PERFECT! I AM AN IDEA BRO! I JUST NEED HELP IMPLEMENTING MY PERFECT GOD-LEVEL IDEAS!” is exactly what get you laughed out of any VC’s office (unless you are also a centi-billionaire high on ket and cuddle puddles 18/7 apparently?)
DENY THY API AND REFUSE THY AJAX
get my one letter domain name out your mouth
imagine bringing definitions based in reality to an internet self-marketing influencer argument
“just wait out the bad dev years” has always been my long-term strategy too.
sure, i spend 10 years just being on call fixing broken logs instead of doing anything real with hyper-scalable value props, plus i get 1/5th what vc-growth-and-fraud-until-the-world-dies-complicit devs are comp’d, but at least I spare my brain from the npm mind virus?
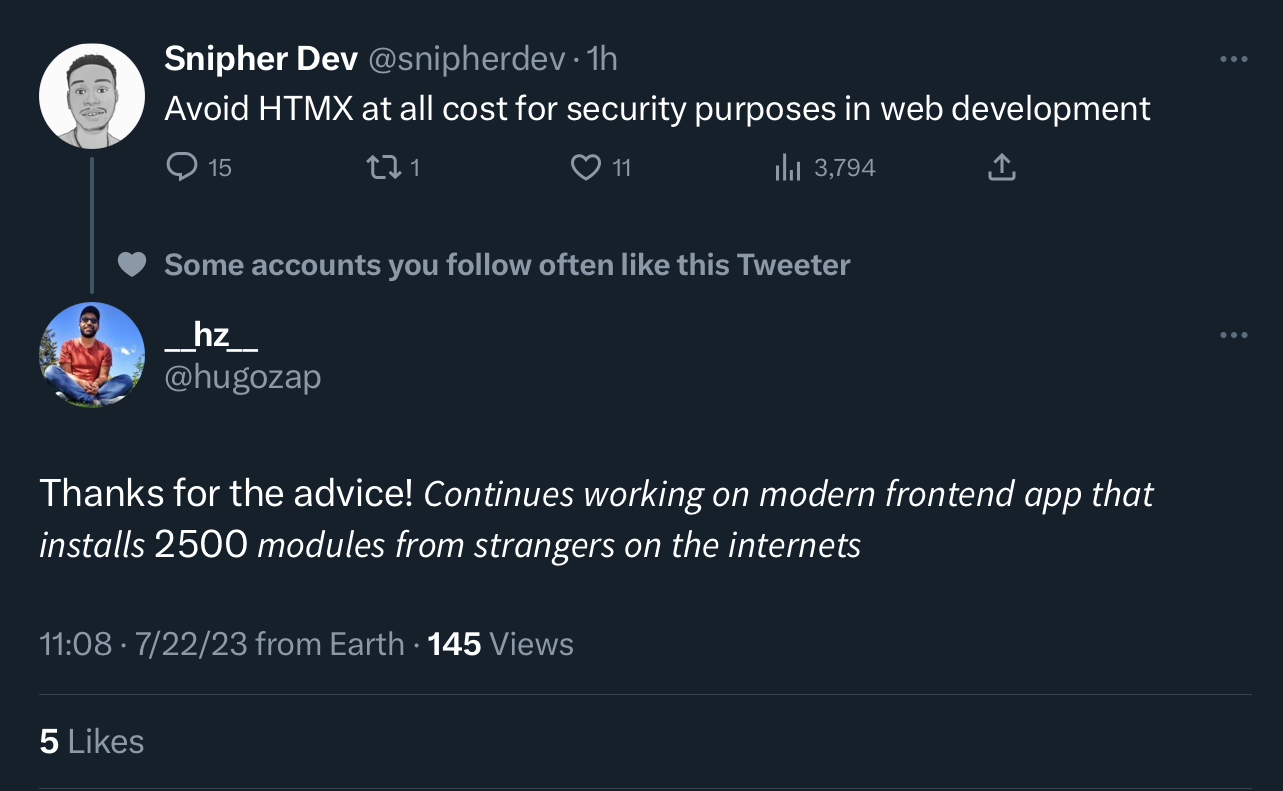
got ’em
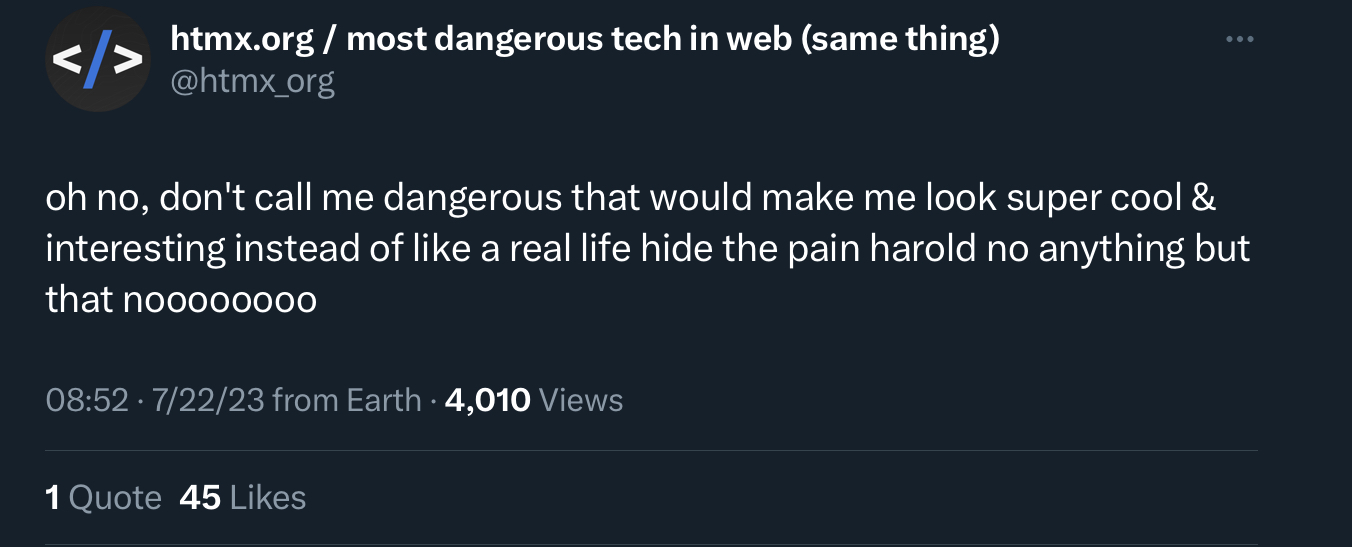
anything but that

oh no not this guy again. if i grow 10x faster i think i just become cancer? you mean the problem i needed your advice to solve was: FIND AN IDEA. WORK ON IDEA? praise the tech lords you were here to save us from ourselves. this is basically like saying “how to become rich? just deposit $1 billion into your bank account!”
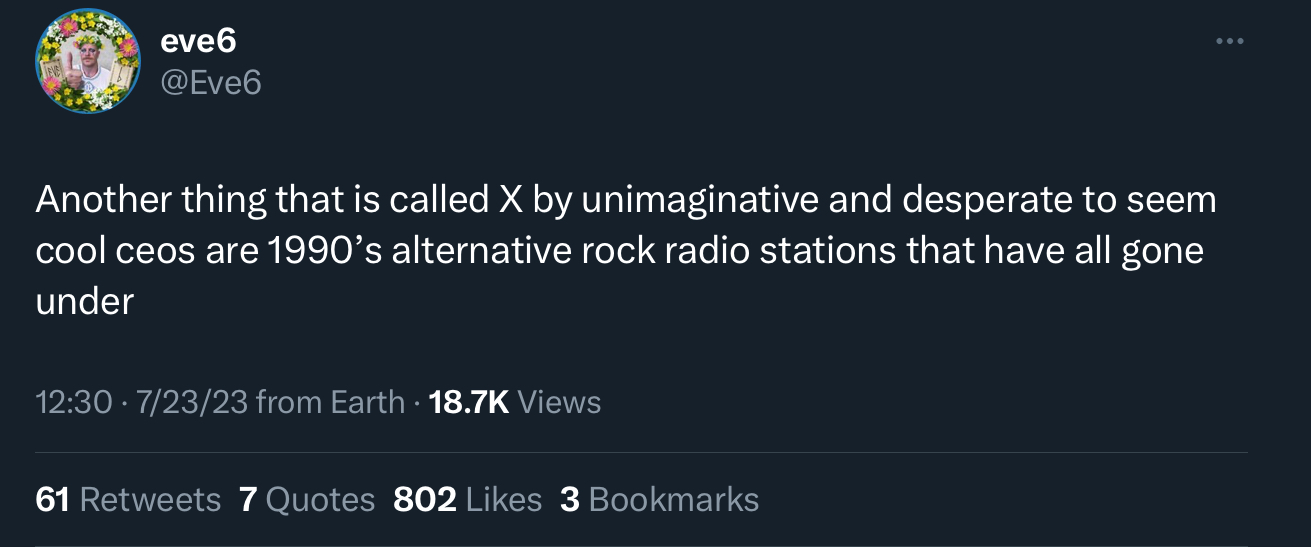
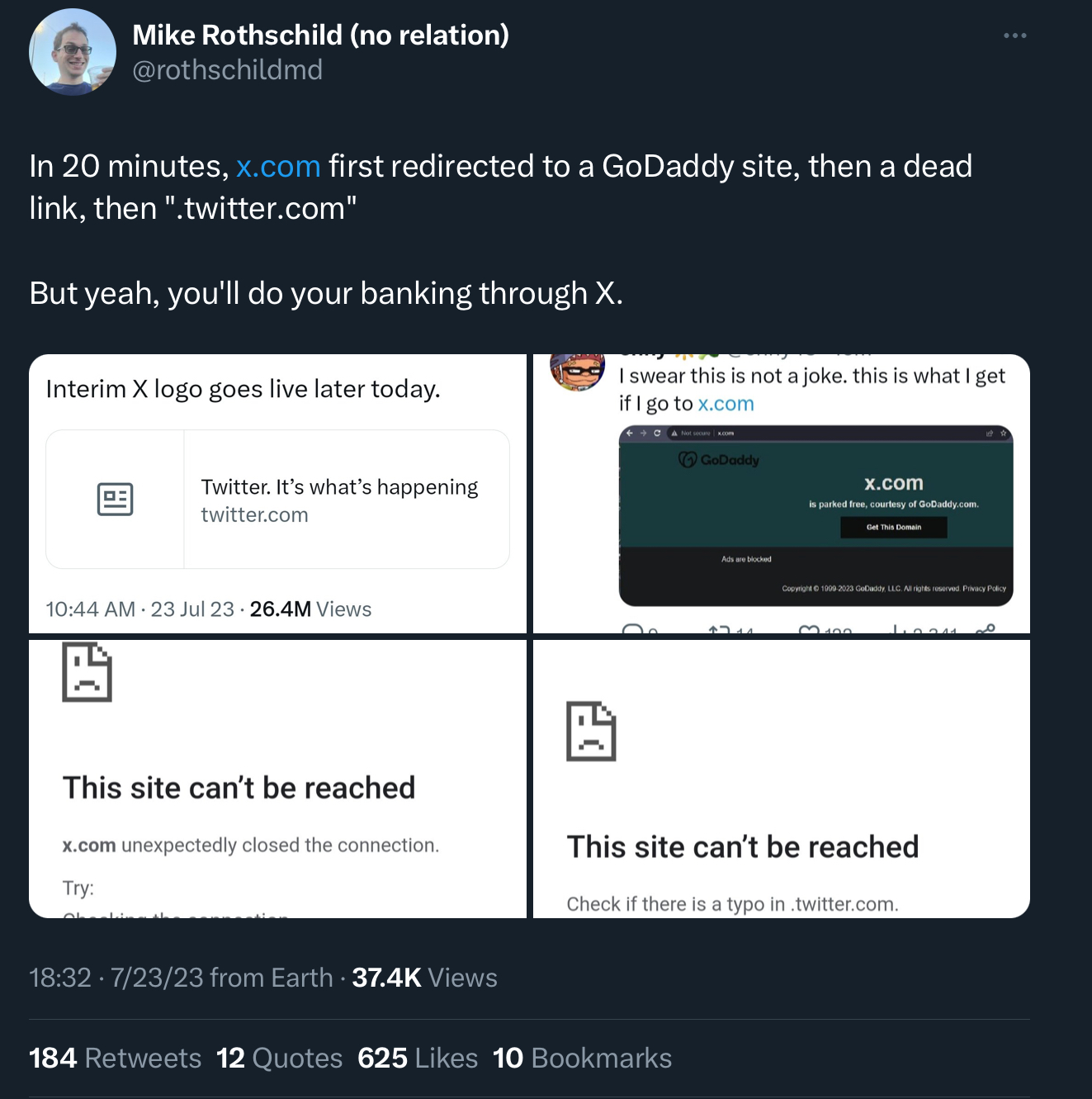
x dot com do do do do do do x dot com do do do do do do x dot com
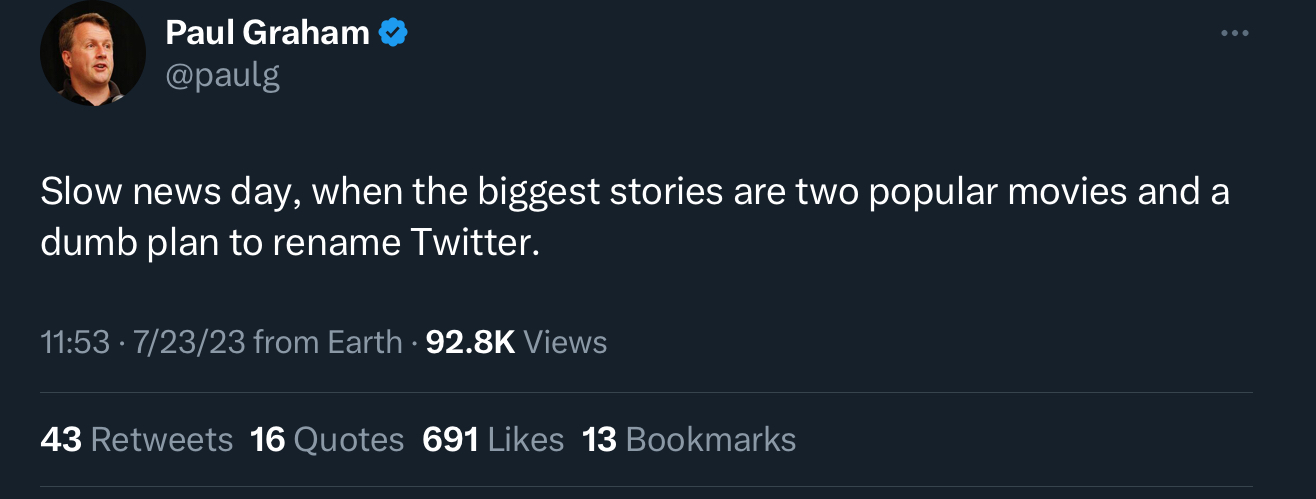
hyper-online capitalist parasite says what? also you can feel the smug derision in his voice by saying “popular movies” — ha! the unwashed masses are too dumb and out “enjoying” “movies” instead of startup-grooming 19 year old guys into starting trillion dollar companies you can just passively leach off of the rest of your life.
what rubes the public are compared to my elite galaxy brain! just wait until ron conway hears about my latest idea for a programming language that will last ONE BILLION YEARS!
i think averaging fewer than 1 lesson per year means you’re not making much progress.
also, 25,000 hours in 15 years? what kind of rookie lazy piece of shit numbers are those? 8am to 10pm every day bro. even with time off (only working 250 days per year), that’s over 50,000 hours in the same time period for creating global change.
usage
i think htmx has a bright future in the new-ish genre of “backend-creates-frontend” platforms like:
- wave/h20 https://wave.h2o.ai/docs/tutorial-counter
- plotly/dash https://dash.plotly.com/minimal-app
Basically backend-creates-frontend systems say “hey python, gimme a page with a thing and another thing, and these things can have buttons, and clicking the buttons trigger these python functions, and the result of the functions get populated in the front-end again…” — perfect match for htmx.
Currently BCF systems tend to auto-generate React® front-ends from
python specs you write, but python-htmx<->python-htmx
seems a much cleaner route.
conclusion
the recent growing popularity of htmx in all walks of life from cereal flavors to car insurance rates to nuclear security protocols once again is surfacing a problem we haven’t solved: post-cloud-native developers don’t understand basic things anymore.
Every cloud-pilled, react-vue-braindead, click-to-deploy developer actually thinks web views require 7 minutes to “compile for production,” then when live require 5-15 second “skeleton loaders” on entry is just a fact of life nobody can question or ever improve on modern 5 GHz machines with 5 Gbps network connections. Developers, at the median, have been getting less capable and more focused on made up silo/cult/trendy dead-end fads for 10 years and the entire world suffers daily.
do you know why AI chat apps are eating google’s lunch? Because clicking on any google link feels like a slog when every page is slow and bloated and takes 5-15 seconds to do the TLS handshake4, render the laggy SPA async user-hostile stuttering content into view, then load in potentially a dozen ads if you land on the thousands of micro-targeted high-ranking scam sites. Asking a chat bot with infinite knowledge and known latency plus knowing it has zero javascript spyware injection is why google search is dead. Google allowed too many scams and slow sites to rank as the first pages of results to the point where now in 2023 probably 80% of programming search results are just scams or hacks or explots or ad farms. The entire discovery infrastructure of the Internet is broken until AI …. reverses entropy.
reject modernity. embrace html injection again, as is the One True
Way to develop, as the gods of YUI and jQuery intended. just splat
things into innerHTML whenever you feel like it. we have vanquished the
olden uncivilized days of document.write, but we went too
far. now we must destroy the shadow dom. shadow, you have no power here,
be gone! stop with the “loaders” — here’s a fun game: every time you
click on a link, hold your breath until the result loads (not
becomes visible and waits for more stuff but actually
renders the full page of content). every search engine: click
link -> bounce to the spyware search engine link tracker -> bounce
to site -> [VISIBLE PAUSE DURING TLS HANDSHAKE] -> the site has an
async SPA loader -> wait 3-5-15+ more seconds -> get content (plus
74 ads if you don’t have an adblock installed).
content is god. javascript is abomination. htmx is space pope keeping the many angled ones at bay.
yeeeeeeeeeeeeeee haw.
which is better than what i did, where i spent 10,000 hours creating the world’s most efficient in-memory database compatible as a memcache and redis replacement, but then i didn’t tell enough people so the code is amazing but actively abandoned until it receives the breath of life again: https://carrierdb.cloud/ / https://carriercache.com/↩︎
2033: “The HTMX Story” by Christopher Nolan premieres to a record breaking $2 billion opening weekend. (actually, sorry, due to climate change and AI we actually have less than 3 years left in total, but it’s a nice thought)↩︎
also, just for good erlang hygiene: you basically never want to run bare processes like this. You want to run everything wrapped in a
gen_serveror similar to prevent rookie mistakes like having your processes crash because they are attached to the wrong parent hierarchy, etc.↩︎nothing makes you hate TLS as much as trying to use the internet from the under side of the world with long latency and overburdened cables everywhere.↩︎