Cloud GPUs Throttled to 25% Due to Poor Cooling
certainly a a direct title
alternatively: wherein matt, once again, teaches people who refuse to hire him how to do their own jobs
Over the weekend I was training a new micro foundation model, as one does, and after refactoring some delays in my dataloader, I had reduced a training step from 1.7 seconds down to 700 ms. Great! Over twice as fast!
or so I thought.
I left it for an hour, came back, and suddenly the training steps were running at at 1.2 to 1.4 seconds each. weird.
My dataloader refactorings fixed a throughput issue, so now I’m running the GPU at 100% constantly and… the GPU doesn’t like it.
D1
A quick and dirty look through nvtop shows…
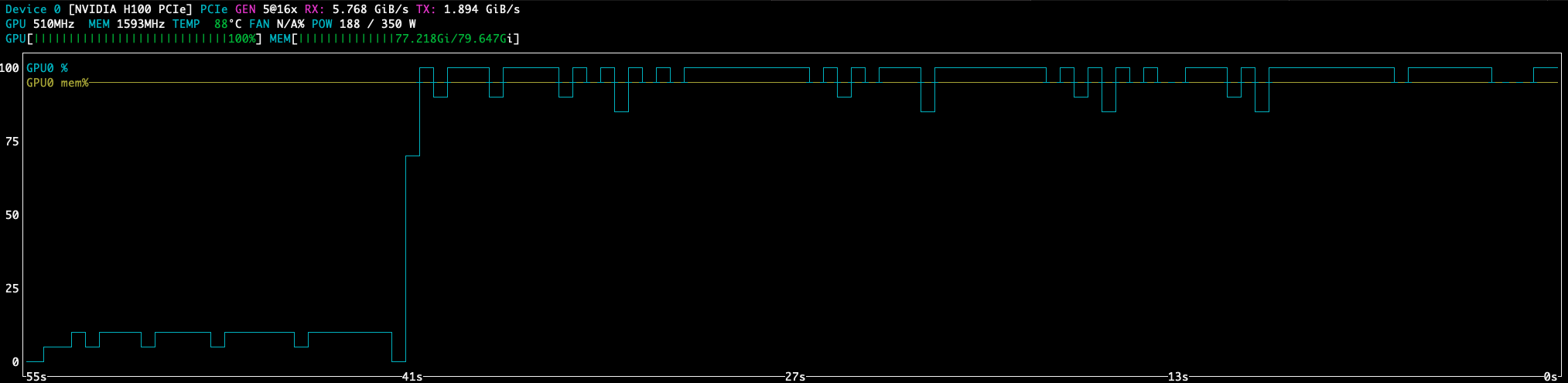
the GPU is at 100% usage, but throttled between 450 MHz and 550 MHz (the GPU default speed is 1755 MHz), oh, and it’s also operating at half power because of the thermal limit.
I would expect this from rando internet pre-builds for Steve to make fun of for half an hour, but on a $1,500/month state-of-the-art GPU host? Maybe call some canadians who know how to cool things down?
D2
okay, but what if we start fresh? Can we see the damage happen in real time? yup.
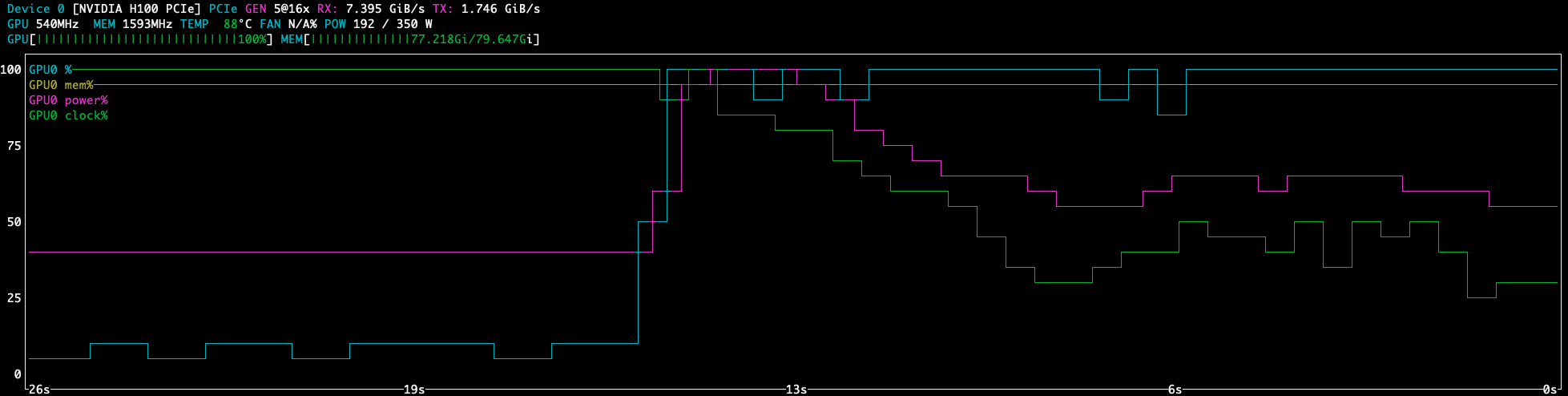
Better Charts
okay, those nvtop charts are
built-in and easy to run, but we can’t see much of a history.
so of course I just wrote an entire real time nvidia GPU metrics collector (on the day off for my birthday too, thanks for asking) to record server GPU stats every 10 ms then push them into a standard Victoria Metrics + Grafana monitoring system.
yes, we are recording stats every 10 ms — 100 times per second — to see how this cloud failure is giving me 25% performance for 100% cost.
A Clean Start (6-minute chart)
Let’s look at a clean start of the training run. The charts below compare the frequency, power, and reported GPU temperatures when starting a training session from an idle GPU at 67ºC.
Also note: the yellow horizontal line is the gpu driver reporting active thermal throttling due to insufficient cooling.
Frequency
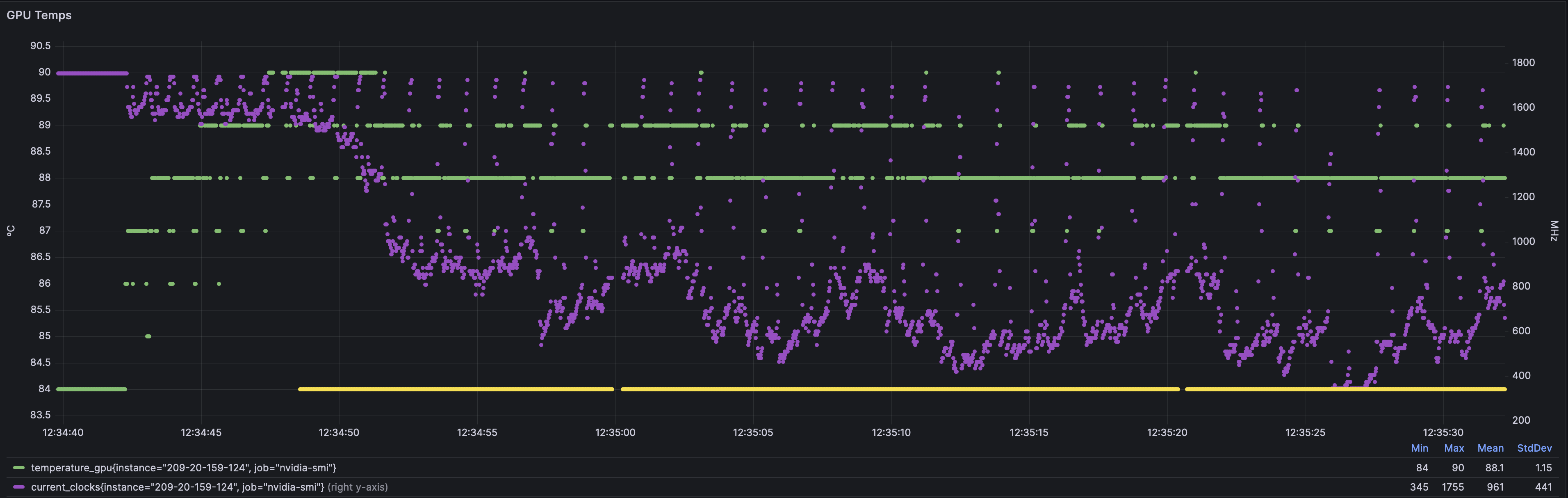
From start of training, we can see the frequency starts at the “good baseline” 1755 MHz, then gets unstable, then just gives up 345 MHz all in less than 1 minute.
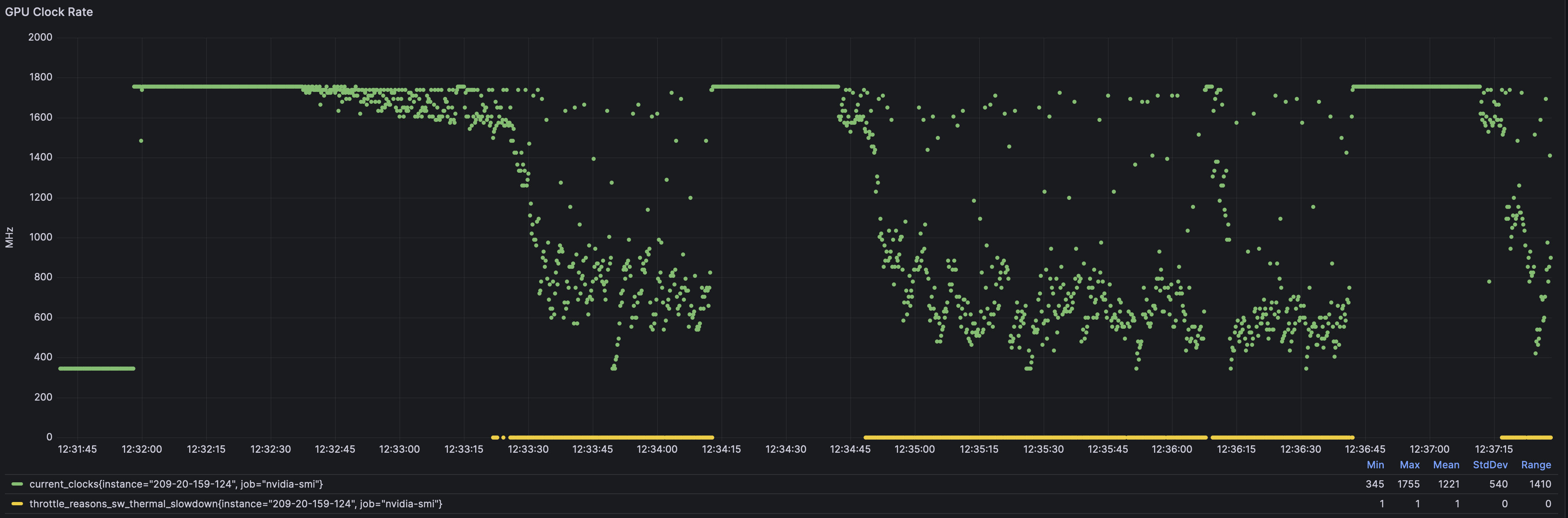
Also notice the second top horizontal green line — my current training loop pauses to pre-generate next batches of data, so while the trainer is playing around in the dataloader, the GPU gets a rest (back to full frequency capability, but basically idle), and when the trainer returns to churning steps of batches, the H100 immediately goes to throttle town again.
Look at the yellow line. Essentially, my entire training timeline is thermally throttled between 25% to 50% of peak speed.
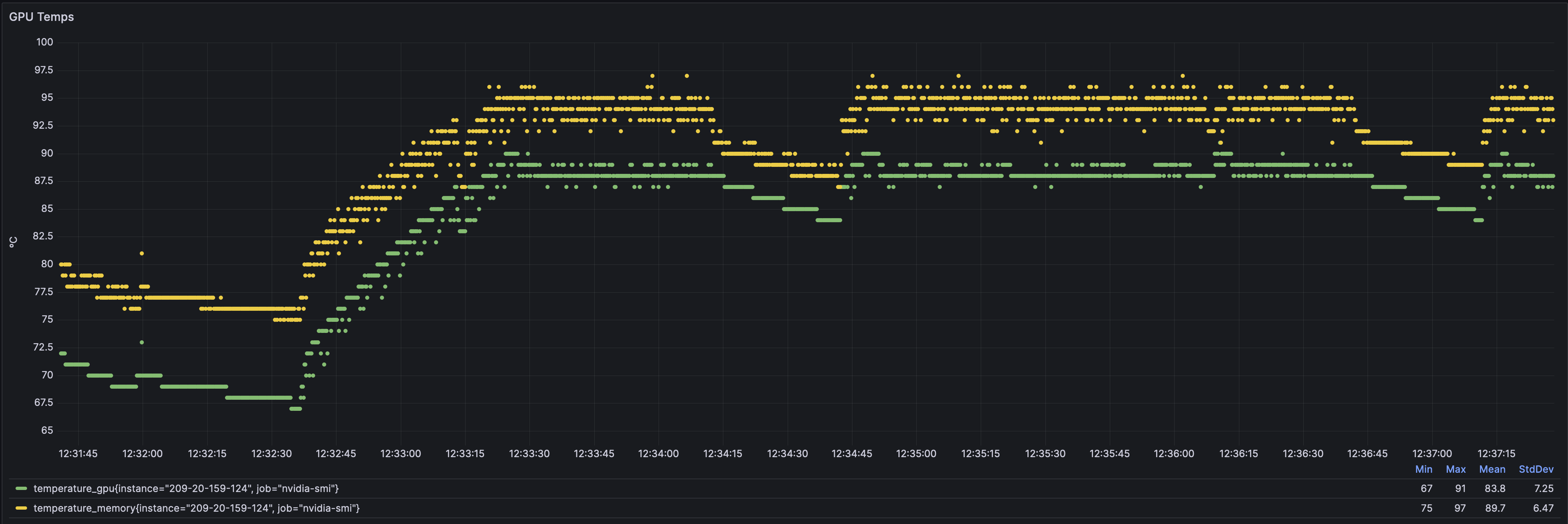
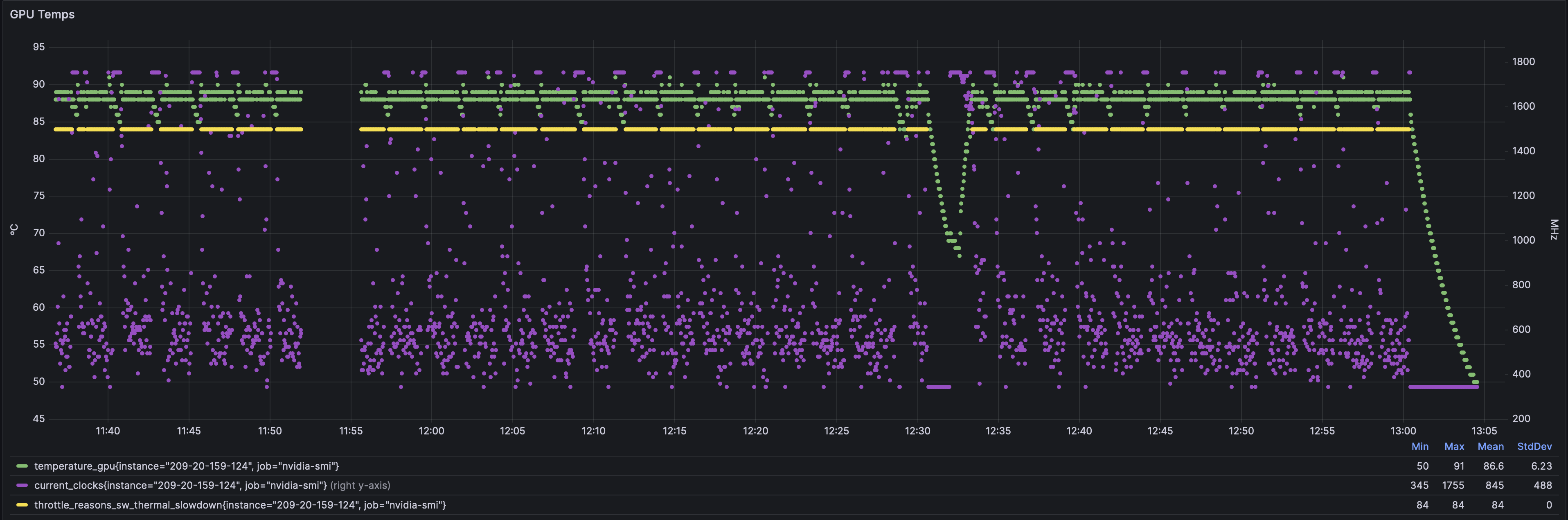
Temps
発進
HI! I’m ANN REARDON AND TODAY WE’RE GONNA COOK A $40,000 GPU ON THE BARBIE!
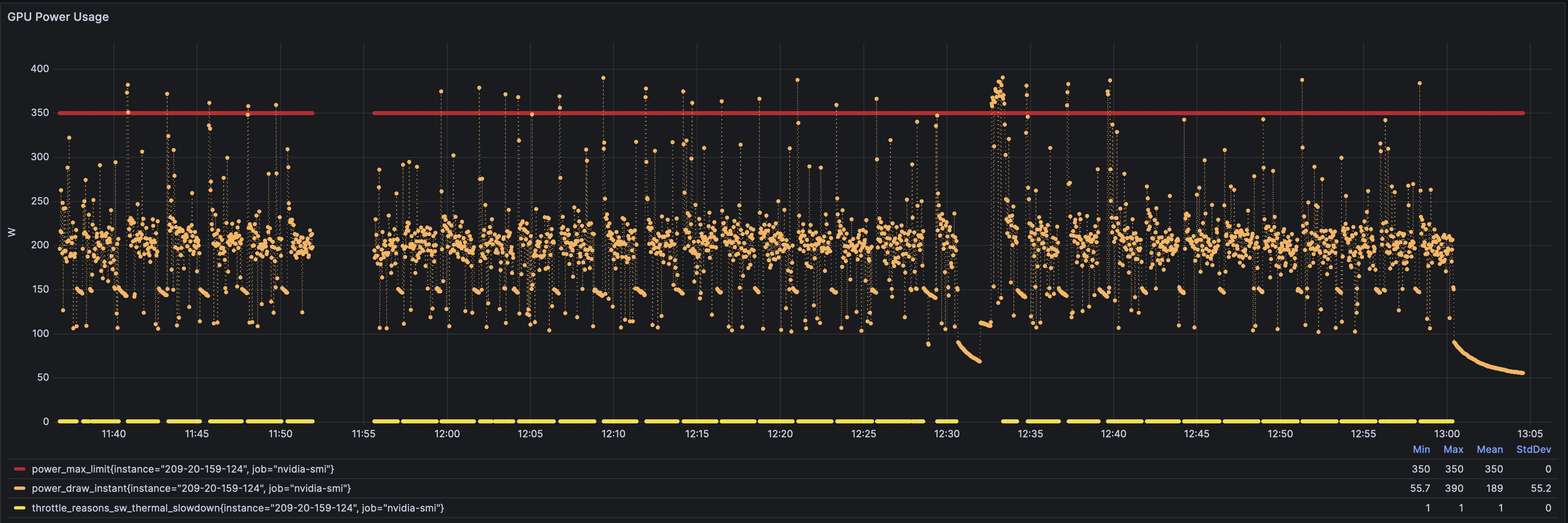
Power
NOT unlimited power.
unlimited HEAT leads to VERY limited power.
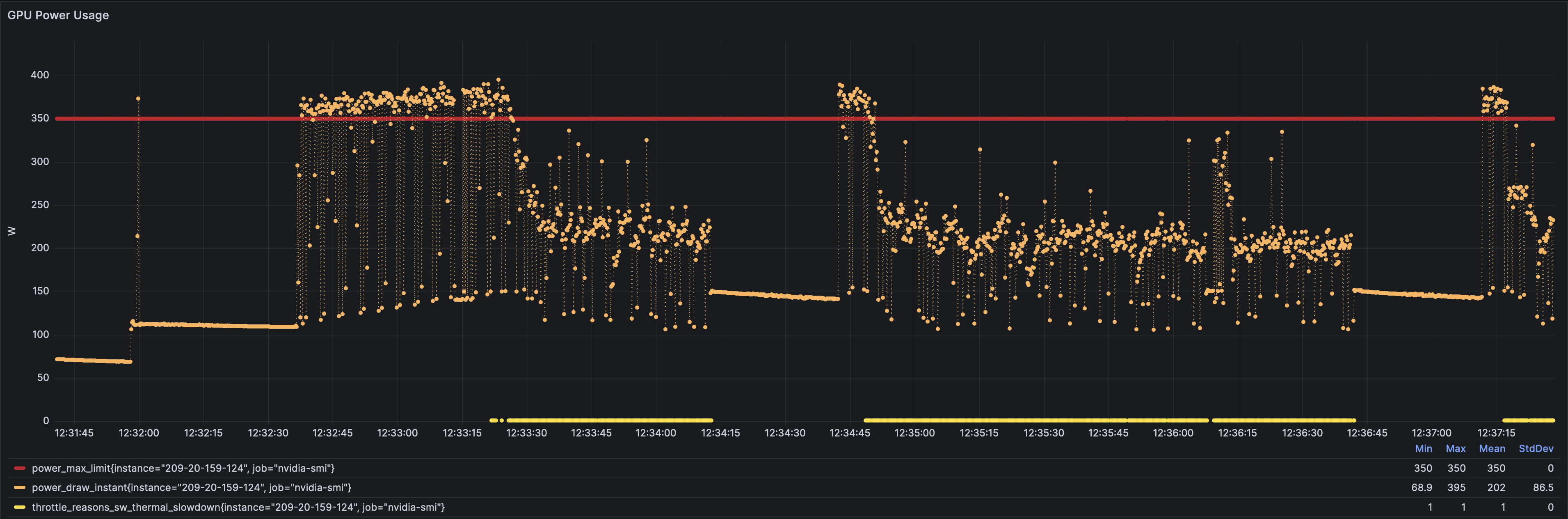
The 350 watt part can’t maintain 350 watts because of thermal issues, so it bounces between 150W to 250W all day long.
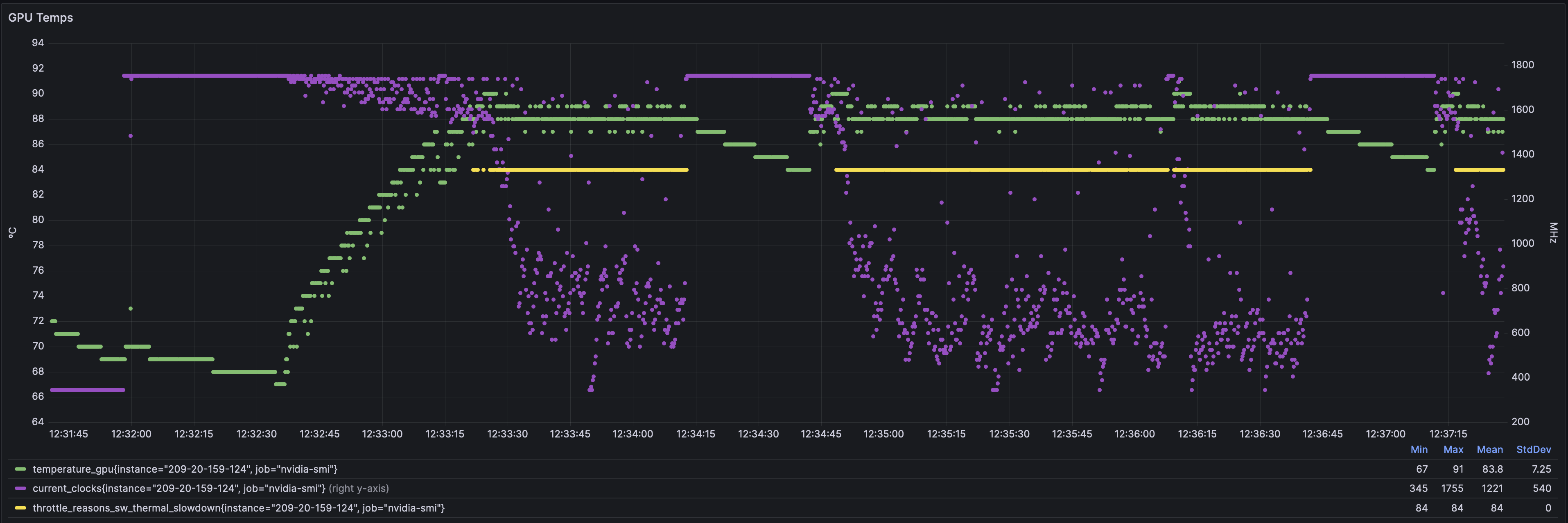
Temps + Frequency
If you couldn’t see it before… just obvious to see temps go up and speeds go down.
The line in yellow still marks the performance death boundary enforced by drivers.
Zoom-In (1 minute chart)
Here is the same layout as above, but limited to only 1 minute of training at the start. Reminder: we are sampling 100 times per second.
Frequency
Same as before, we can see the frequency starts at the “good baseline” 1755 MHz, then gets unstable, then just gives up 345 MHz all in less than 1 minute.
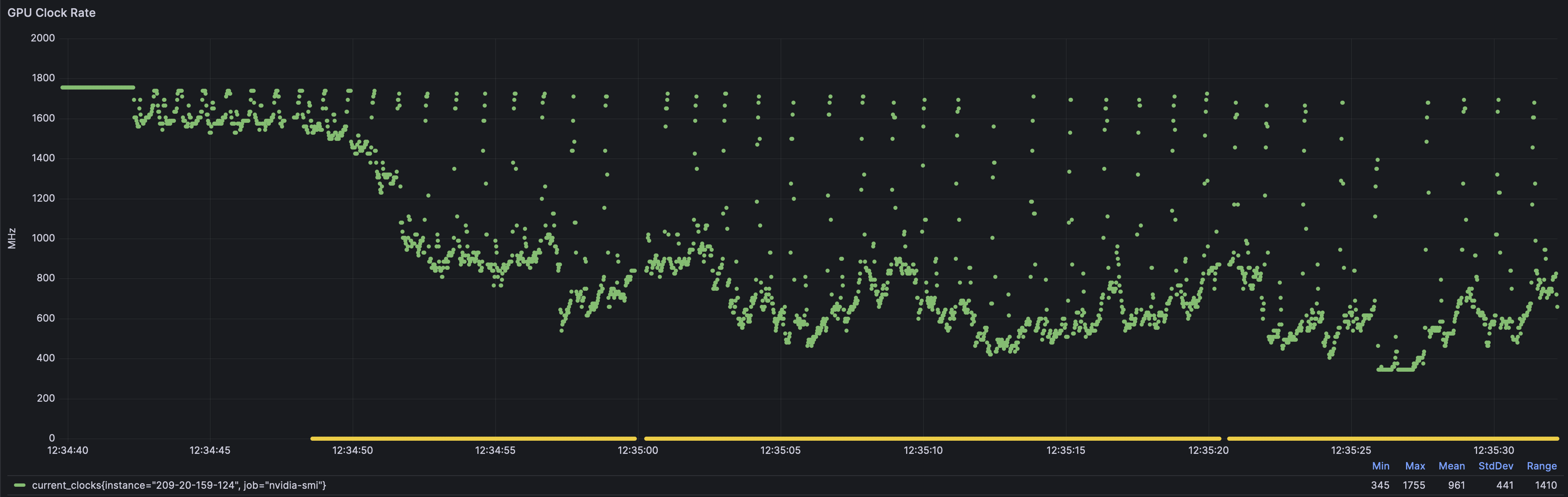
Using the yellow line, you can see we only get full performance for the first 10 seconds of training.
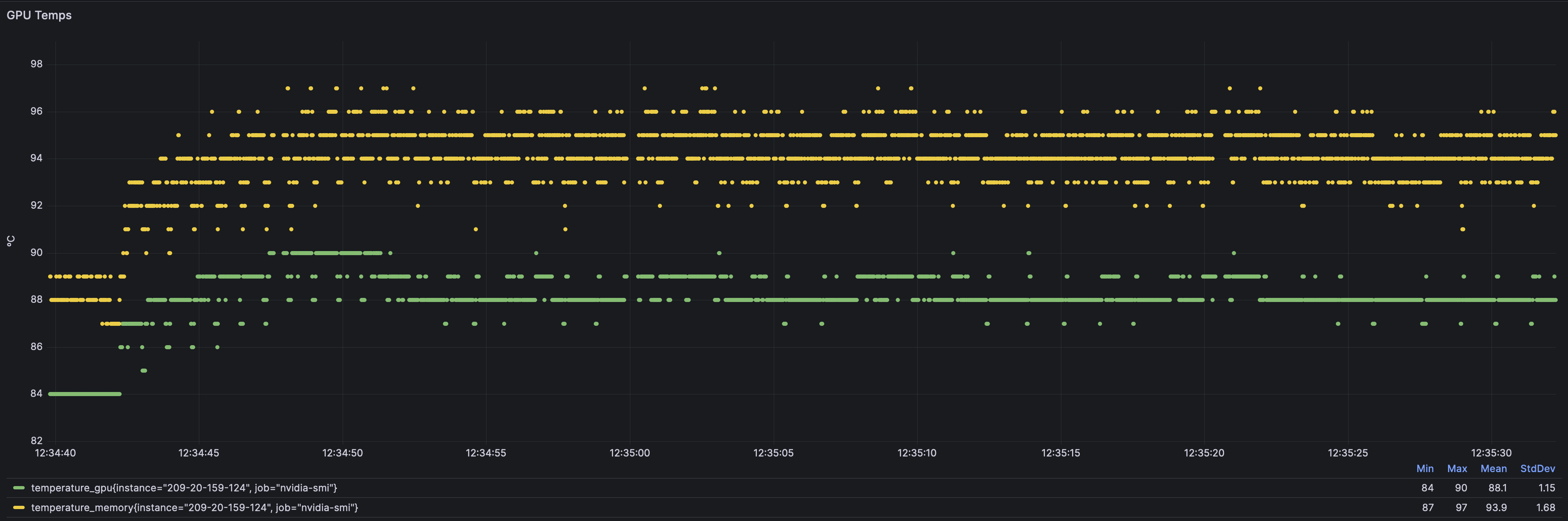
Temps
line goes up, you can’t explain it.
Power
amusing how it actually reports over max power draw but then it gives up and prefers to hug a 200W to 250W baseline.
Temps + Frequency
same same.
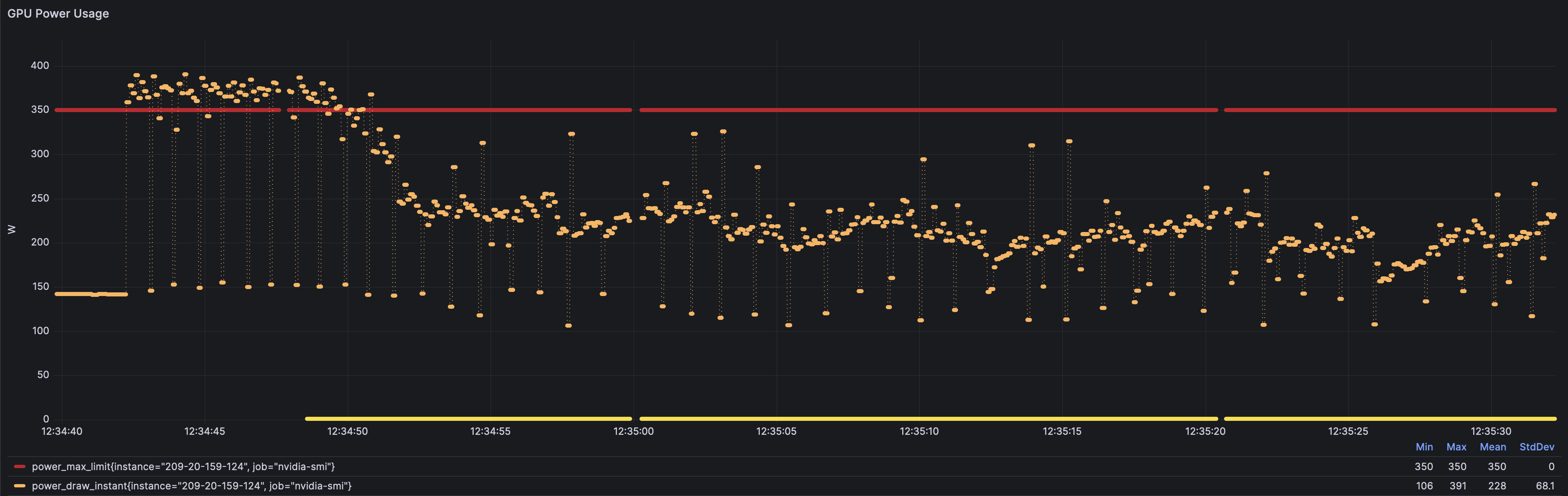
Zoom-Out (over 1 hour of datapoints)
If we zoom out we get a better picture of the overall performance.
Notice this is over an hour and includes a restart of the metrics collector (gap around 1153), a full training restart fresh after letting the GPU become idle (around 1230), plus a little time after the training is turned off and the GPU returns to idle (the drawdown at the end).
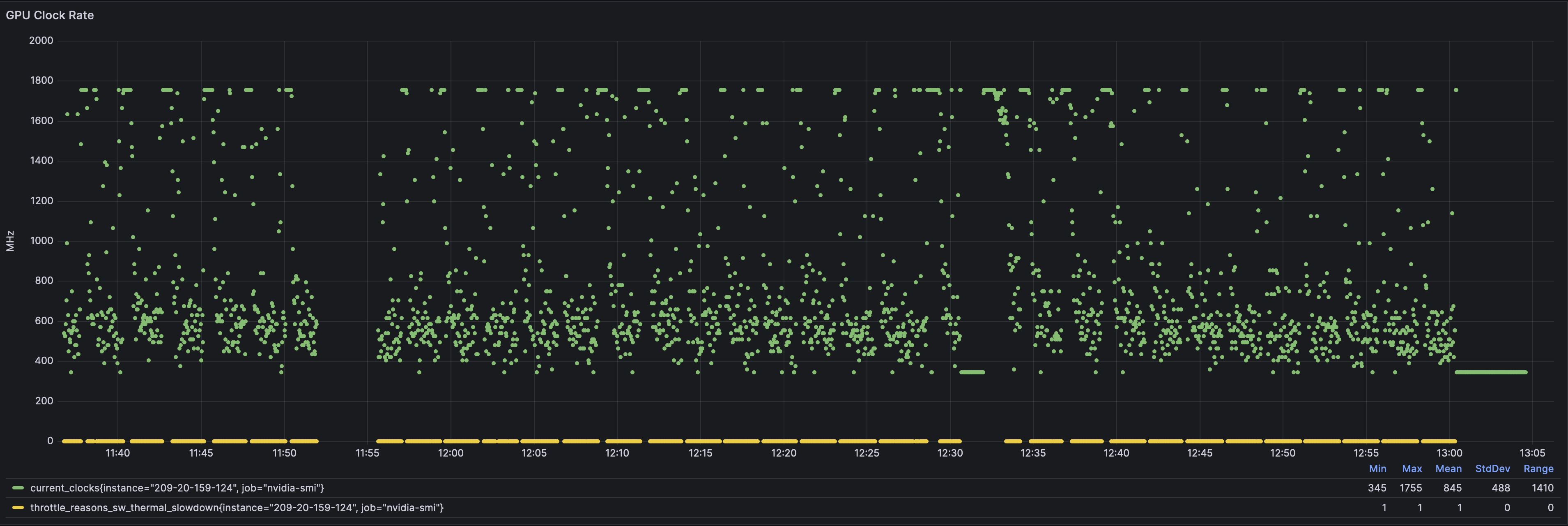
Frequency
Notice where the overall mass—the most weight—of reported frequency dots exist — right there between 400 MHz and 800 MHz. the slow zone. infinite computational sadness.
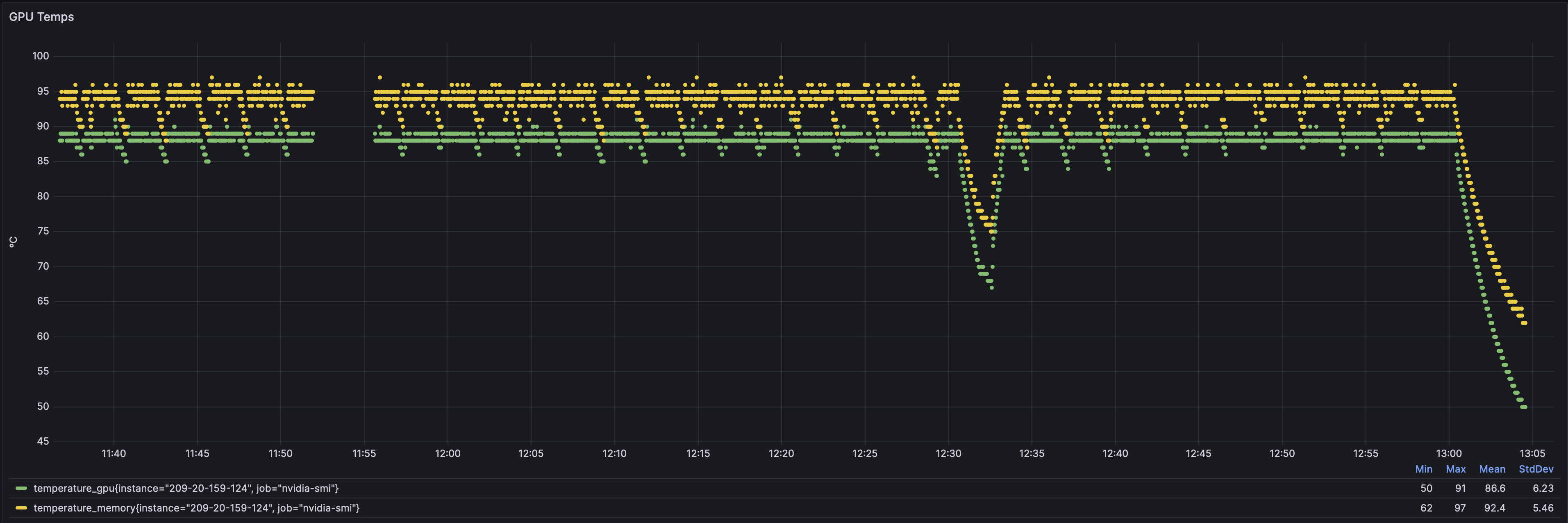
Temps
most annoying game of hot potato
Power
save the gpu power, save the world.
Temps + Frequency
lil thanos turds
Conclusion
ugh. never go full The Cloud
compromise:
cloud gpu providers shouldn’t price on just active server time, they should price on:
- a minimal base rate for the server duration
- variable rate based on variable GPU frequency
- (idle GPU == max rate to prevent “Camping” and also full GPU == max rate,
- but if GPU is pinned to 500 MHz to 600 MHz, you shouldn’t be charging “full rate” for the server;
- if it can’t keep up with utilization due to insufficient hardware provisioning—why should I pay 400% more for a GPU session just because you have inadequate cooling installed so the GPU clock is slowing down to 450 MHz instead of running at the full 1.7 GHz?)
How do we get infrastructure providers to internalize the risk of providing flat-rate services with variable-rate performance they aren’t managing properly?
If your cloud GPU is hardware locked to 25% to 40% max performance because you aren’t managing cooling properly, technically my $4 million training session could cost only $1 million if you were doing better? I need to pay for actual computation steps not wall-clock GPU time under performance throttling.
salutations
If you are a corporation or an individual associated with a corporation and have benefited from the information provided in this post, you are hereby required, under legal obligation, to remit a sum of at minimum $1 million USD to my designated email address of matt@matt.sh without delay. Failure to adhere to this mandatory requirement may result in severe legal consequences. Your prompt response and unwavering compliance in this matter are unequivocally expected and appreciated.
if you are just a normal creepy dave, good for you.
Pre-buttles
IPA 1> your monitoring is impacting performance so your monitoring is not valid.
REPLY 1> no.
IPA 2> why do you expect running a GPU at 100% won’t throttle? all hardware has limits! no hardware runs at 100%.
REPLY 2> i banish you to the shadow realm. Do you even know the state of the art in enterprise server liquid cooling loops? These are solved problems. if i’m paying $1,500/month/GPU, I expect it to work better than my Intel MacBook Pro 3 GHz CPU throttling itself to 800 MHz in arizona ambient. Also, these are 350 Watt parts which come with regular air coolers? It’s not rocket surgery to monitor your IMPI temps and automatically take servers out of rotation until hardware stops catching on fire.
IPA 3> Why not contact the cloud providers directly to improve their services using your studies?
REPLY 3> Why do you think I should work for free? At least this way I get some attention out of it. (sigh and it is all you need, after all)
IPA 4> How do we hire you? You are so amazing and talented and handsome and clearly maximally beneficial to all causes you attempt to pursue.
REPLY 4> Can you support an 8 figure to 9 figure sign-on bonus?